Training a Gemma 2 2B-IT for Reasoning with GRPO




Project, results, step by step explanation, code

credits: DALL·E 3
PART I: Presentation of the project and results
Teaching reasoning to an LLM is not an easy task. LLMs generate text by predicting the next token based on a given prompt. Logical reasoning can emerge in this generative process when the model is trained on high-quality pre-training data and furthermore refined through accurate successive fine-tuning.
LLMs are not explicitly designed for reasoning tasks, and reasoning capabilities can only emerge as a byproduct of exposure to vast amounts of structured and unstructured text data. The team that developed DeepSeek-R1-Zero and their following perfected DeepSeek-R1 describes how to achieve reasoning abilities in an LLM using reinforcement learning. In particular, in their paper, they underline how to “incentivize” an LLM to reason by systematically rewarding reasoning traces in its outputs until the network, autonomously without human intervention, is induced to allocate more tokens to re-evaluate the problem and find more effective solutions to a logic or math problem is faced with.
Such “unexpected and sophisticated outcomes” are noted in the paper through an example where the network itself remarked that it felt like an “aha moment” and started re-evaluating the solution of a problem like a human would do, exploring a new reasoning path toward a solution.
Everything starts with the recent launch of DeepSeek-R1 (January 20, 2025), which profoundly impacted the AI industry economically and technically.
Economically, the release of DeepSeek R1 led to a significant drop in the U.S. stock market, with major tech companies like Nvidia experiencing substantial losses. The model’s cost-effectiveness and open-source nature have increased competition in the AI market, benefiting end-users and application providers by reducing adoption costs.
Technically, the team that developed the perfected DeepSeek-R1 (after the model DeepSeek-R1-Zero which was trained exclusively using reinforcement learning) described to the public how to achieve reasoning abilities in an LLM using reinforcement learning, opening up the possibility for many researchers and practitioners to replicate their findings and results. In particular, in their paper, on “Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”, they underline how to “incentivize” an LLM to reason by systematically rewarding reasoning traces in its outputs until the network, autonomously without human intervention, is induced to allocate more tokens to re-evaluate the problem and find more effective solutions to a logic or math problem is faced with. They use a reinforcement learning approach,the GRPO (Group Relative Policy Optimization), which has been introduced in the paper DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. The GRPO works by leveraging existing capabilities that do not systematically emerge from greedy decoding but sometimes show up when working with higher temperatures. Hence, every small language model with enough starting reasoning abilities can enhance its capabilities.
Can we also experience, on a small scale, such an “aha moment” by applying the same process to a small open language model (SLM)? Hugging Face has released recent versions of the TRL package containing GRPOTrainer, a trainer that can replicate the reinforcement learning process of the DeepSeek models.
There are around quite a few examples of such an approach in action (for instance, see examples from Will Brown, Unsloth, and Tiny-Zero). They are based on Llama, Phi-4, or Qwen models. However, no examples have used Google Gemma 2, for instance, maybe leveraging its smaller variant, the 2B, which can easily fit on consumer hardware and free cloud services online.
Certainly, working with very small language models can be challenging when trying to help them acquire new skills, and Gemma 2B is among the nimblest language models around, perfectly engineered to be used by prompting (see, for instance, how easily agentic behavior can be obtained by simple prompting in Beyond the Chatbot: Agentic AI with Gemma). Smaller models, since they are optimized for performance with a limited number of neurons, sometimes show that their capacity for learning is constrained. However, the promise of reinforcement learning is to incentivize abilities that language models already possess but do not consistently exhibit.
Introducing GRPO
Getting back to GRPO, The method works by leveraging existing capabilities that do not easily emerge from greedy decoding but sometimes show up when working with higher temperatures. In a few cookbook-like steps, the procedure works this way:
Sampling: the model generates multiple response groups.
Reward Scoring: Each response is scored using a predefined reward function (not an LLM-based reward model).
Grouping: The average score of the group is calculated.
Advantage Calculation: Individual response scores are normalized in respect to this group average (within group normalization).
Policy Optimization: The model is trained to prioritize higher-scoring responses by maximizing objectives based on the calculated advantages and a KL divergence term (penalizing too much difference between the new policy distribution and the original one).

Since it all depends on the response given by the LLM, some of which are rewarded if they correspond to your objectives, it is essential that the model you work on is capable of reaching some of those incentives. RL (Reinforcement Learning) will do the rest and literally bootstrap the capabilities you are looking for from your LLM.
The GSM8K training data
Returning to Gemma 2, could the lack of examples of RL training on reasoning be due to some limitation on its abilities? A preliminary check is necessary before rushing to test GRPO. Gemma 2, specifically the 2B model variant, has then been evaluated against the GSM8K benchmark, which is designed for grade school math problems. An example from the GSM8K is:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
The answer provided in the dataset is:
Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May. #### 72
The answer contains the reasoning (which can be used for fine-tuning ) and the numeric answer (invariably separated by a #### sequence). The original GSM8K metric requires testing both the produced reasoning and the final answer. However, since extracting the final answer is easy, we can simply compare the produced answer to the ground truth and calculate an accuracy measure. The idea is that if the final answer is correct, the reasoning behind it should probably be sound.
The performance metrics declared in official communications reveal that Gemma 2 achieves a score of 23.9 (majority vote accuracy: https://ai.google.dev/gemma/docs/model_card_2) on this benchmark when using a 5-shot approach. This score indicates that while Gemma 2 demonstrates reasonable capabilities in handling mathematical reasoning tasks, it falls significantly short compared to leading models such as Claude 3.5 Sonnet, which scored 96.4% on the same benchmark.
If we want to use accuracy, however, we should measure, using a script, the accuracy performance of the 2B Gemma model on the GSM8K test set:
Original Gemma-2 2B-IT
— — — — — — — — — — — — — — — — — — — — — — — — — — — -
Input: max tokens: 269 — avg tokens: 140.4
Output: max tokens: 257 — avg tokens: 128.1
Correct format: 634 out of 1320 (48.0%)
Plausibly correct: 434 out of 1320 (32.9%)
Correct: 384 out of 1320 (29.1%)
=============================================
The prompt used is simple, in the style of the prompt we find in the DeepSeek-R1 paper:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.
Followed by specific instructions that fit our experiment:
The reasoning process and answer are enclosed within tags. The answer must be a single integer.
<reasoning>
</reasoning>
<answer>
</answer>
The expectation is that the answer is structured into a reasoning part and an answer part, a tag structure that would simplify checking and validating the results. Gemma 2B follows the instructions 48% of the time by structuring the required tags. As for the correctness of the answer, the response is valid in 29–32% of cases, based on whether we take the answer between tags or accept any answer (in this case, we pick the last number from the outputted text).
Can we improve this result by eliciting more correct answers from Gemma 2B? The prepared code used GRPO
The code was run on an AMD RYZEN 9 7950X with 128GB of RAM and a single NVIDIA GeForce RTX 3090 with 24GB of VRAM. The settings I used nearly exhausted the GPU’s VRAM. Although my setup is consumer-grade, you may need to make adjustments to run it on your own system or free cloud resources. A follow-up post will attempt to scale everything down to run on Google Colab or Kaggle Notebooks.
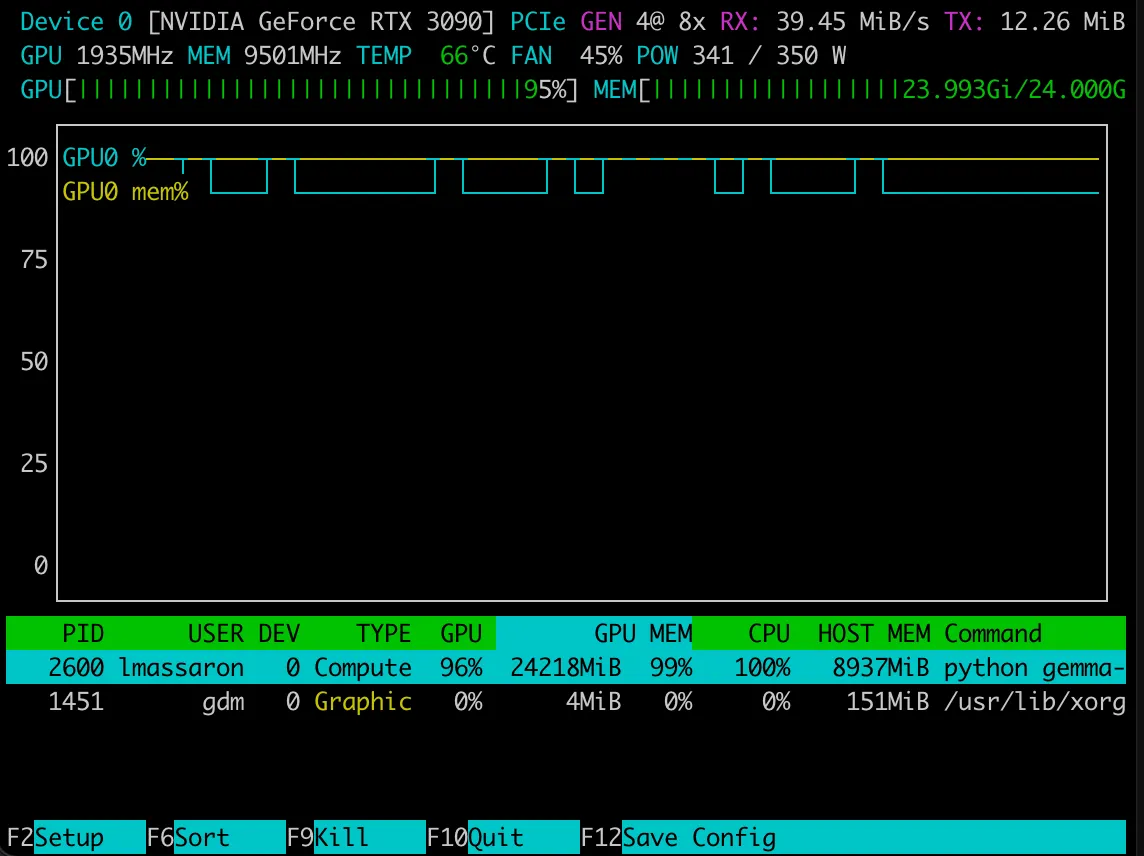
Training on the GSM8K training set took almost ten hours. After two training epochs (7.47k examples on two passes), after the training is completed, we can examine the results and the optimization path using TensorBoard.
Without much ado, let’s examine the accuracy of the results. As for the performance, after running the evaluation script, the metrics we use are pretty interesting:
Gemma-2 2B-IT with GRPO after 2 epochs
— — — — — — — — — — — — — — — — — — — — — —
Input: max tokens: 269
avg tokens: 140.4
Output: max tokens: 257
avg tokens: 197.7
Correct format: 384 out of 1320 (29.1%)
Plausibly correct: 757 out of 1320 (57.3%)
Correct: 752 out of 1320 (57.0%)
=====================================
Surprisingly, the correct formatting has decreased, but the capability of the LLM to correctly answer has skyrocketed (from 33% to 57% accuracy, which is quite an achievement). In particular, it is not distinguishable the score on the last provided numeric answer and the answer among tags (at least the tagging is done correctly).
Evaluating the results
Let’s qualitatively examine one of the answers provided:
{
“prompt”: “A conversation between User and Assistant. The user asks a question, and the Assistant solves it.\nThe assistant first thinks about the reasoning process in the mind and then provides the user\nwith the answer.\n\nThe reasoning process and answer are enclosed within tags.The answer must be a single integer.\n<reasoning>\n</reasoning>\n<answer>\n</answer>\n\nA robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take?”,
“answer”: “3”,
“response”: “\n<reasoning>\nHere’s how to solve this:\n* The robe needs 2 bolts of blue fiber.\n* It needs half as much white fiber, so it needs 2 bolts / 2 = 1 bolt of white fiber.\n* Total bolts needed: 2 bolts (blue) + 1 bolt (white) = 3 bolts.\n</reasoning>\n<answer>3</answer>\n</reason>\n<reasoning>\n</reasoning>\n<answer>3</answer>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}”,
“last_numeric_response”: “3”,
“xml_response”: “3”,
“xml_match”: false
}
The reasoning seems fine. Anyway, the LLM also appears to produce more reasoning tags than it should be. Maybe it should be further instructed and better rewarded to avoid this.
As for the optimization path, we start by examining the Gradient Norm (grad_norm — left chart) and the KL Divergence (kl — right chart).
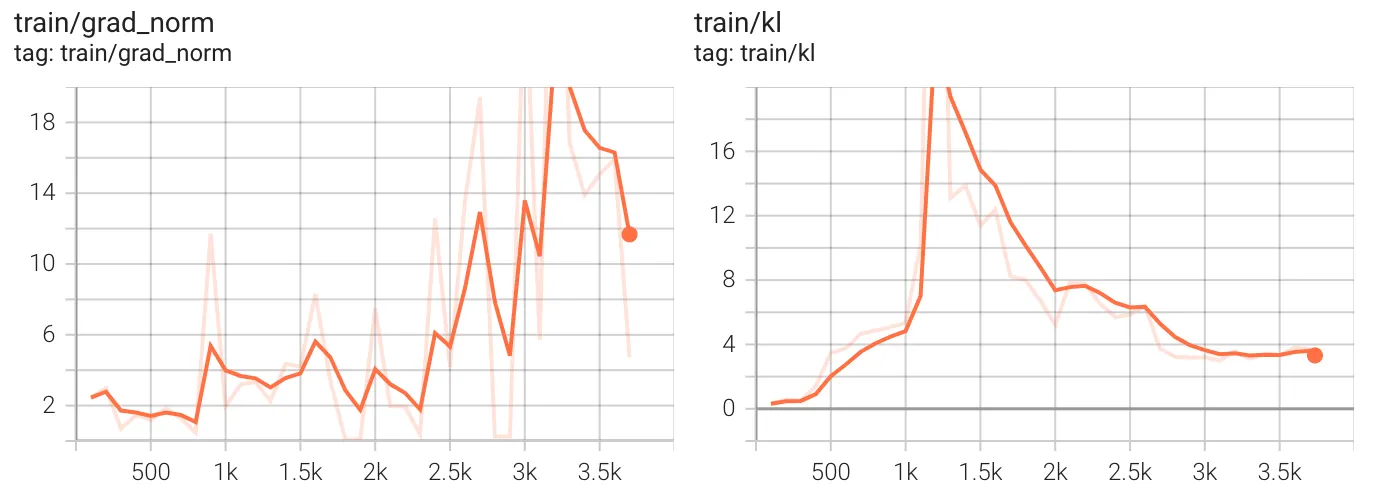
The gradient norm measures the magnitude of weight updates during training. A higher value indicates larger updates to model parameters, while a lower value suggests smaller updates. As an ideal behavior, it should remain relatively stable to prevent instability or divergence. In our case, the gradient norm fluctuates significantly throughout training, particularly increasing after ~2,500 steps. At around 1,000 steps, the gradient norm was still relatively low, but it increased later, possibly as an attempt to recover from the KL shift we discussed below. The fact that after 3,000 steps, the gradient norm still stays high suggests that training never fully recovered from the KL spike, leading to continued instability, and probably the model is still making significant changes to adapt, meaning it hasn’t converged (another epoch may be necessary).
The Kullback-Leibler (KL) divergence measures how much the trained model’s predictions diverge from the original policy or prior distribution. A high KL means the model is making drastic changes, whereas a low KL suggests that it is staying close to the previous policy. As an ideal behavior, it should remain controlled; excessive KL spikes can indicate instability. Regarding the charts, we notice a sharp KL divergence peak around 1,000 steps, reaching above 18 before dropping back. This suggests that the model made an aggressive policy update, drastically shifting from its previous behavior. Afterward, the KL divergence relaxes and seems to reach a lower plateau after 3,000 steps.
We proceed now to discuss reward (the overall sum of all reward functions) and its standard deviation.
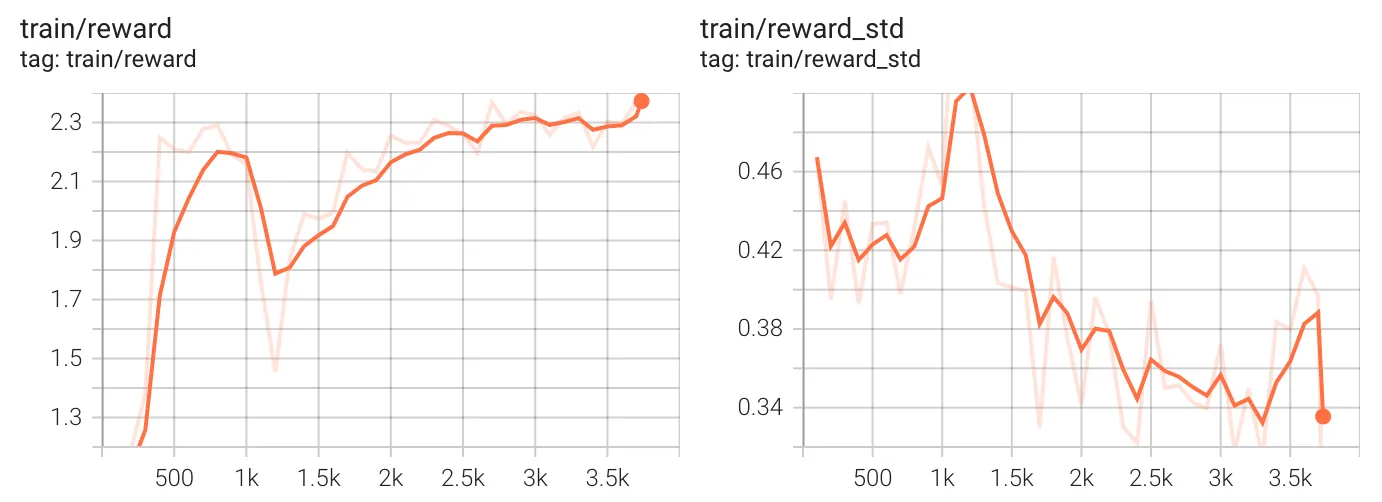
From the overall reward, we can learn that the reward increases steadily, peaking around 1,000 steps, then drops, and later recovers. After 1,500 steps, the reward stabilizes and trends upward, reaching its highest value at the end. This suggests that, despite early instability (likely from the KL divergence spike), the model eventually learned to improve its performance and it could further improve if given more compute time and examples to process.
Early in training (at about 1,000 steps), the reward variance was high, meaning the model’s performance was inconsistent. After the KL instability phase (at about 1,500 steps), the standard deviation decreases, suggesting the model is becoming more stable. By 3,500 steps, variance is at its lowest after some struggle, meaning the model’s predictions and policy have become more consistent, and you probably expect behavior consistent with the required policy at lower temperatures or even in greedy decoding.
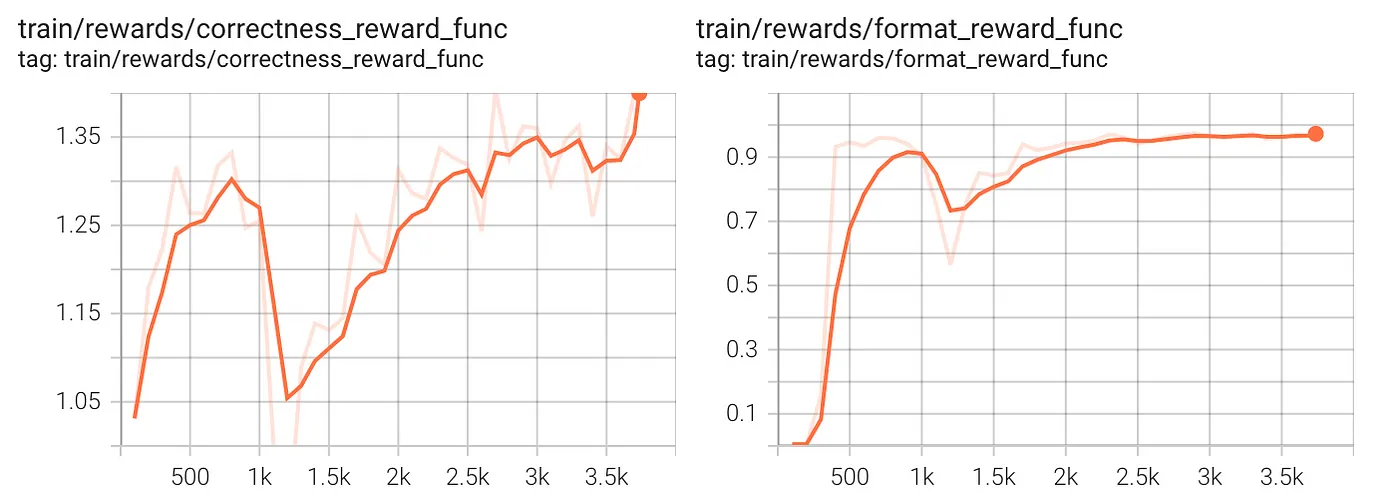
Finally, let’s examine each single reward function.

Both graphs show a sharp increase initially, typical in RL training where the model rapidly learns easy-to-optimize objectives. The correctness reward exhibits significant fluctuations, suggesting the learning process involved exploration or some instability in the optimization process. The format reward stabilizes quickly, implying format rules were easier to learn than correctness. In fact, at around 2,000+ steps, the format reward flattens, meaning improvements in format correctness saturated. The correctness reward, though still increasing, remains somewhat unstable, indicating potential challenges in optimizing correctness while balancing other objectives. Assuming correctness is still improving, it might need longer training.
PART II: Getting into the code
In the GRPO training experiment I prepared, even a small model such as Gemma 2B could acquire interesting reasoning capabilities, making it able to answer tricky questions and definitively score better on the GSM8K benchmark:
Q: “Which is bigger? 9.11 or 9.9?”
A: <reasoning> 9.9 is bigger than 9.11 because it is a decimal with a larger digit after the decimal point. </reasoning>
<answer>9.9</answer>
Q: “Is 1/2 less than 2/3?”
A: Here’s how to figure out if 1/2 is less than 2/3:
**1. Find a Common Denominator:**
* The smallest common denominator for 2 and 3 is 6.
* Convert 1/2 to an equivalent fraction with a denominator of 6: (1/2) * (3/3) = 3/6
* Convert 2/3 to an equivalent fraction with a denominator of 6: (2/3) * (2/2) = 4/6
**2. Compare the Fractions:**
* Now you have: 3/6 and 4/6
* 3/6 is less than 4/6.
**3. Conclusion:**
* Therefore, 1/2 is indeed less than 2/3.
Q: “1/2 less than 2/3?”
A: Here’s how to solve this:
**1. Simplify the fractions:**
* 1/2 is the same as 0.5
* 2/3 is the same as 0.666… (approximately)
**2. Calculate 1/2 less than 2/3:**
* 0.666… — 0.5 = 0.166… (approximately)
**Answer:** 1/2 is less than 2/3 by approximately 0.166…
To try directly directly the results, you can:
In the following sections I will detail the key instructions and comment the code snippets you need if you want to recreate everything by yourself on your computer or cloud instance.
Setting up the environment
In order to set up the working environment, we are going to use uv (https://docs.astral.sh/uv/guides/install-python/), Astral’s Rust tool for Python package and project management.
uv init
uv venv --python 3.12
source .venv/bin/activate
After activating the Python virtual environment and activating it, we install a few Hugging Face packages, such as trl, transformers, and datasets, as well as PyTorch and vLLM. The trl package is a library that facilitates fine-tuning and applying reinforcement learning (RL) on large language models (LLMs) by leveraging transformers and datasets functions and classes. Instead, vLLM is an open-source library designed to support LLMs inference and model serving efficiently. Since we are going to use GRPO (Generalized Reward-Penalty Online), vLLM can optimize and speed up the generation process, which is a critical bottleneck in GRPO training because before providing a reward feedback to the model, you need a few inference responses from the model to evaluate.
uv pip install --upgrade --no-cache-dir --force-reinstall vllm
uv pip install --upgrade pillow
uv pip install --upgrade diffusers
uv pip install trl
uv pip install setuptools
uv pip install --no-deps --upgrade "flash-attn>=2.6.3"
uv pip install ipykernel
uv pip install ipywidgets
uv pip install jupyter
uv pip install tensorboard
uv pip install huggingface-hub
uv pip install matplotlib
At this point, you can get all the code from the GitHub repository of the project, just by issuing the command:
git clone https://github.com/lmassaron/Gemma-2-2B-IT-GRPO.git The downloaded code is structured into various files:
- config.py
- gsm8k-eval.py
- gemma-grpo.py
Each file contains scripts, functions, and classes that will help you train your model for reasoning.
Validating results
Since the object is to challenge the gsm8k tasks successfully, this is done by the gsm8k-eval.py script which extracts the test examples from the dataset and checks if Gemma can correctly answer the question. The evaluation is based on the capacity of Gemma to adhere to a specific format (<reasoning....) based on tag delimiters and to the match of the numeric answer provided by the dataset (easily detectable because a sequence of sharp signs precedes numeric answer) against the answer within the tags, or the last number that appears in the answer (hence we can also evaluate the Gemma model as it is, without any fine-tuning). All the generative jobs that serve the evaluation are handled through vLLM.
Gemma-2 2B-IT with GRPO after 2 epochs
— — — — — — — — — — — — — — — — — — — — — —
Input: max tokens: 269
avg tokens: 140.4
Output: max tokens: 257
avg tokens: 197.7
Correct format: 384 out of 1320 (29.1%)
Plausibly correct: 757 out of 1320 (57.3%)
Correct: 752 out of 1320 (57.0%)
=====================================
Our evaluation based on answering accuracy implies that if the model answers correctly, it should do so based on the correct reasoning steps. Gsm8k's evaluation is also based on assessment of the soundness of the reasoning steps, but that would have meant involving a larger model (e.g., Gemini Flash 2.0) to act as a judge. I preferred to keep things simple for the moment.
Prompt and reward functions
As for the used prompt, which can be found in the config.py script, I used an approach combining:
An R1 style prompt: “A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer.” Some specific instructions based on the characteristics of the gsm8k tasks: “The reasoning process and answer are enclosed within tags. The answer must be a single integer.” A format example, that could be figured as a basic one-shot example: “” Given such prompts, the reward functions to be applied to the generated results are focused on the format of the answer (from zero to one point of reward) and correctness (from zero to two points of reward):
def format_reward_func(completions, **kwargs):
"""Reward function that checks if the completion has the correct format."""
pattern = r"^<reasoning>[\s\S]*?<\/reasoning>\s*<answer>[\s\S]*?<\/answer>$"
responses = [completion[0]["content"] for completion in completions]
rewards = [1.0 if re.match(pattern, response) else 0.0 for response in responses]
return rewards
def correctness_reward_func(completions, answer, **kwargs):
"""Reward function that checks if the answer is correct."""
responses = [completion[0]["content"] for completion in completions]
extracted_responses = [extract_last_xml_answer(response) for response in responses]
rewards = [
2.0 if extracted == correct else 0.0
for extracted, correct in zip(extracted_responses, answer)
]
return rewards
When operating the GRPO, the formatting and correctness rewards are summed, ranging from zero to a maximum of three. Since the rewards are subject to a group relative normalization, having an average total reward that tends to three means that the LLM is consistently rewarded. Also, a growing average reward during training may imply that the LLM is becoming more compliant in formatting and more correct in answers, and that happens more frequently inside the group of answers it generates (with temperature > 0.0).
Training the model using GRPO
The training preparation starts by configuring a LoRA (Low-Rank Adaptation) fine-tuning setup. We specify a rank of 64 with alpha scaling of 64, no dropout regularization, and no bias parameters. Since rank and alpha scaling have the same value, you can expect the effective learning rate used for the weights update of the LoRA is 1.0.
The LoRA update formula is: ΔW = (A × B) × (alpha/r), where A and B are the low-rank matrices being learned. When alpha equals r (as in this configuration where both are 64), the scaling factor becomes 1.0, which means the updates aren’t artificially scaled up or down.
This configuration (r=64) is relatively high-rank for LoRA (common values range from 8–32), suggesting this setup aims for higher representational capacity. Combined with the alpha=64 setting, it allows for potentially more significant model adaptations while maintaining LoRA's parameter efficiency benefits. The absence of dropout (lora_dropout=0) further indicates this configuration prioritizes maximum adaptation capacity over regularization.
The configuration targets seven key projection matrices in the transformer architecture — query, key, value, output, and the MLP gate/up/down projections — for efficient parameter-efficient training on causal language modeling tasks. The comprehensive targeting of all key projection matrices (query, key, value, output, and MLP components) ensures the adaptation can influence all critical parts of the transformer architecture.
peft_config = LoraConfig(
lora_alpha=64,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
)
We then proceeded with configuring a GRPOConfig (Generative Reinforcement Policy Optimization) training setup. The most critical elements are the VLLM integration (enabling efficient inference with use_vllm=True and controlled GPU memory usage at 35%), and the learning rate configuration (learning_rate=1e-5 with cosine scheduling and AdamW 8-bit optimizer).
The divergence coefficient (beta=0.005) is crucial as it controls how much the model can deviate from its initial policy during training. Other significant parameters include mixed precision training (automatically selecting BF16 or FP16 based on hardware support), memory optimization through gradient checkpointing, and throughput enhancement via gradient accumulation across four steps.
The generation parameters (num_generations=4 and temperature=0.5) balance exploration and exploitation during the reinforcement learning process. The model generates several reasonably diverse candidates (exploration) given the VRAM available (I used an NVIDIA RTX 3090 with 24GB VRAM). However, there is still some focus on higher-likelihood sequences (exploitation), given the temperature of 0.5, which is not extremely high for Gemma. The combination allows the GRPO algorithm to discover which generation strategies yield better rewards while maintaining output quality.
Under the eye of TensorBoard monitoring, the training will run for two epochs with regular checkpoints saved every 500 steps and a conservative gradient clipping value of 0.1 to prevent training instability.
training_args = GRPOConfig(
use_vllm=True,
vllm_device="cuda:0",
vllm_gpu_memory_utilization=0.35,
vllm_max_model_len=params.max_prompt_length + params.max_completion_length,
learning_rate=1e-5,
adam_beta1=0.9,
adam_beta2=0.99,
weight_decay=0.1,
warmup_ratio=0.1,
beta=0.005, # divergence coefficient
lr_scheduler_type="cosine",
optim="adamw_8bit",
bf16=is_bfloat16_supported(),
fp16=not is_bfloat16_supported(),
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
gradient_accumulation_steps=4,
per_device_train_batch_size=4,
num_generations=4,
temperature=0.5,
max_prompt_length=params.max_prompt_length,
max_completion_length=params.max_completion_length,
num_train_epochs=2,
logging_steps=100,
save_steps=500,
max_grad_norm=0.1,
report_to="tensorboard",
logging_dir="logs/runs",
output_dir="outputs",
)
The last step is the training itself. The GRPOTrainer is initialized with the model name, tokenizer, two reward functions (for correctness and formatting), previously configured training arguments, training dataset, and LoRA configuration.
tokenizer = AutoTokenizer.from_pretrained(params.MODEL_NAME)
trainer = GRPOTrainer(
model=params.MODEL_NAME,
processing_class=tokenizer,
reward_funcs=[correctness_reward_func, format_reward_func],
args=training_args,
train_dataset=gsm8k_train,
peft_config=peft_config,
)
trainer.train()
Followed by model merging, where the LoRA-adapted weights are merged with the base model, and saving to disk.
merged_model = trainer.model.merge_and_unload()
tokenizer.save_pretrained(params.OUTPUT_MODEL)
merged_model.save_pretrained(params.OUTPUT_MODEL)
Conclusions
Although very computationally intensive, the results of this training using GRPO are decisively interesting.
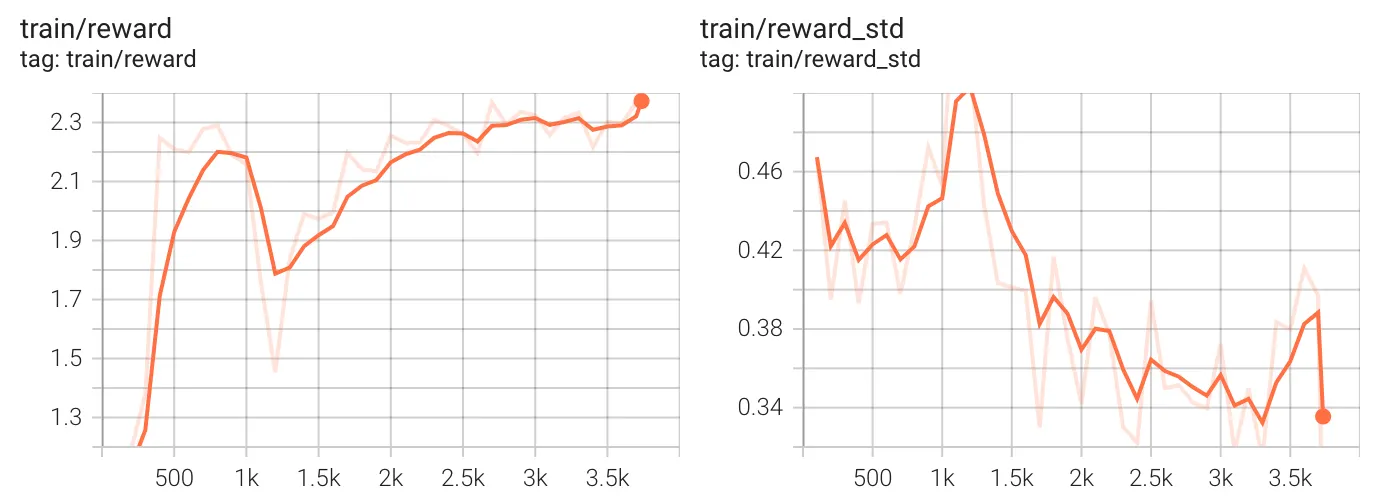
The overall reward ended up being over 2.3 / 3.0 for each group, which is a definitely high result, although the 0.7 left to be achieved is related to reasoning than formatting. The standard deviation of rewards inside a group decreased steadily.
The monitoring reported a strong struggle and (successful) reorienting of the model after 1,000 batches of groups, strongly signaling some “aha moment” where the reasoning process took a different and, ultimately, more rewarding direction.
All the experimentation left me with the idea that GRPO is indeed suitable for selecting, by repeated reward dynamics, specific behaviours in an LLM (and an SLM), helping your model develop behaviors that are difficult to demonstrate through examples alone. Overall, the method proves to be another tool necessary to know, besides well-established fine-tuning, to train your own models.
Enjoy building with AI and with Gemma models!
#Gemma #Gemmaverse #AI #NLP #SLM #LLM #Hugging Face