Magpie Speech — Applying an LLM Data Synthesis Method to an LLM-Based TTS Model to Synthesize a Speech Dataset







Introduction
This post walks through how I applied Magpie—a data synthesis technique originally designed for LLM instruction tuning—to an LLM-based TTS model and built a synthetic speech dataset.
TL;DR
Recently we’ve seen more autoregressive, LLM-based TTS models such as Llasa and Orpheus-TTS. Because these models are LLM-based, many LLM data-synthesis techniques can be re-used with minimal changes.
In this article, I applied Magpie to Orpheus-TTS and created (and released) a ~125k sample synthetic speech dataset:
https://huggingface.co/datasets/Aratako/Magpie-Speech-Orpheus-125k
Below is a high-level overview of how the dataset was made.
About Magpie
Magpie is a method to synthesize instruction–response pairs for instruction tuning using open LLMs, starting entirely from scratch.
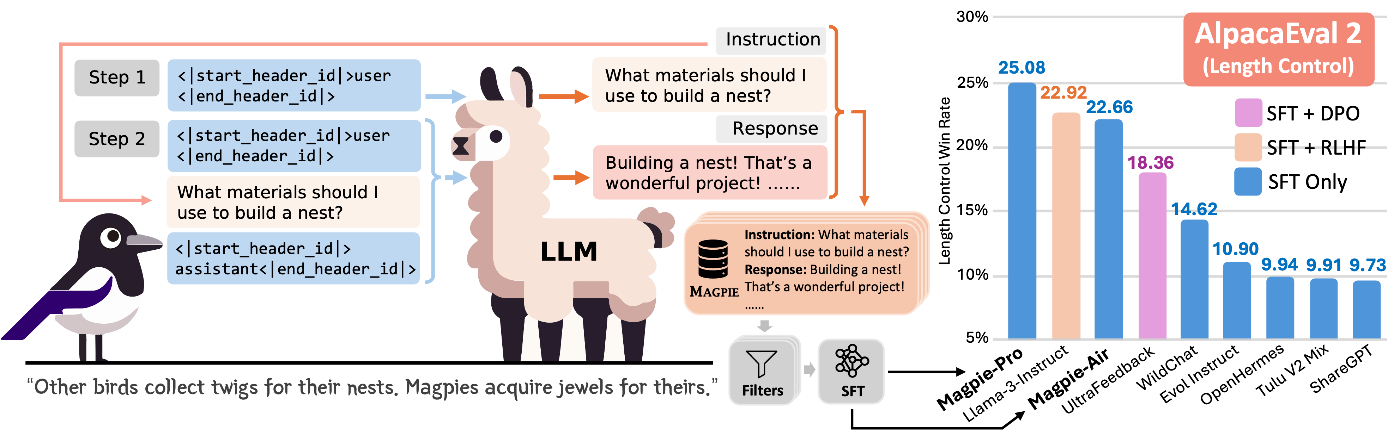 Overview figure from the official GitHub (credit: Magpie repo)
Overview figure from the official GitHub (credit: Magpie repo)
Paper and official implementation:
At a high level, Magpie proceeds in two steps:
1) Synthesize the instruction
Magpie generates the instruction by prompting the LLM with the chat template up to (but not including) the user’s instruction. In other words, we feed the model the prefix right before the user_prompt field so that, under next-token prediction, it will produce what “should” come next—the instruction itself.
For Llama 3, a typical chat template looks like:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{user_prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{assistant_response}<|eot_id|>
To synthesize an instruction, provide the template up to the user section (you may omit system_prompt if you wish):
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
The model then outputs the would-be user_prompt.
Although instruction tuning often applies a loss mask to user inputs, in practice this approach still works reasonably well; and for models trained without masking the user segment, it tends to work especially well.
2) Synthesize the response
Given the synthesized instruction, we then ask the same model to produce a response by feeding the standard prompt format (here user_prompt is the instruction we just synthesized):
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{user_prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Because Magpie’s instructions are produced by continuing the model’s own chat template, they tend to be close to the model’s training distribution. This makes them less OOD and often yields higher-quality responses in step 2.
Applying Magpie to Speech Dataset Synthesis
So far I described Magpie for text-only instruction tuning. Here’s how I repurposed it to synthesize a speech dataset.
LLM-based TTS models like Llasa or Orpheus generally train as follows:
- Prepare a text–speech paired dataset.
- Tokenize the text with the LLM’s tokenizer.
- Discretize the speech waveform into audio tokens (via a neural codec).
- Train on sequences like
Text Tokens → Audio Tokens, so the model predicts audio tokens conditioned on the text.
Under this setup, the relation between input text and output audio tokens mirrors the instruction–response relation in a standard LLM. Therefore, we can synthesize text (the “instruction”) and then synthesize audio tokens (the “response”) using the same Magpie idea.
For Orpheus-TTS in particular, the official preprocessing notebook suggests the model is trained without loss masking on the text input, which should make Magpie especially effective:
Below is the concrete workflow I used.
1) Synthesizing input text
This is identical to Magpie’s instruction synthesis. Provide the prompt up to the position just before the text segment, then let the model continue.
From the Orpheus-TTS training format (see the notebook above), the prefix immediately before the text is:
<custom_token_3><|begin_of_text|>
Here, <custom_token_3> is “Start of Human”, and <|begin_of_text|> is “Start of Text”.
I used a simple Python script with vLLM to generate text:
Text synthesis script
import re
from collections import Counter
import torch
from datasets import Dataset
from tqdm import tqdm
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
TARGET_SIZE = 500000
BATCH_SIZE = 2000
ITER = TARGET_SIZE // BATCH_SIZE
orpheus_model_id = "canopylabs/orpheus-3b-0.1-pretrained"
RE_CHAR_RUN = re.compile(r"(.)\1{3,}")
RE_WORD_RUN = re.compile(r"\b(\w+)(?:\W+\1){2,}\b")
RE_CTRL = re.compile(r"[\x00-\x08\x0B\x0C\x0E-\x1F]")
def ends_like_sentence(s: str) -> bool:
s = s.rstrip()
return len(s) >= 2 and s[-1] in ".?!…。!?"
def ngram_stats(words, n=3):
if len(words) < n:
return 1.0, 0 # unique_ratio, max_count
grams = [" ".join(words[i : i + n]) for i in range(len(words) - n + 1)]
c = Counter(grams)
unique_ratio = len(c) / len(grams)
max_count = max(c.values())
return unique_ratio, max_count
def passes_text_filters(
text: str,
finish_reason: str,
min_chars=8,
max_chars=300,
min_words=3,
max_words=80,
min_unique3_ratio=0.6,
max_3gram_count=3,
):
# 1) stopped naturally?
if finish_reason != "stop":
return False, "finish_reason"
# 2) trivial cleaning / length checks
s = text.strip()
if not (min_chars <= len(s) <= max_chars):
return False, "length_chars"
words = re.findall(r"\w+", s.lower())
if not (min_words <= len(words) <= max_words):
return False, "length_words"
# 3) control/special tokens
if RE_CTRL.search(s):
return False, "ctrl_char"
if "<" in s and ">" in s: # quick guardrail (tighten if needed)
return False, "special_token_like"
# 4) repetition checks
if RE_CHAR_RUN.search(s):
return False, "char_run"
if RE_WORD_RUN.search(s):
return False, "word_run"
uniq3, max3 = ngram_stats(words, n=3)
if uniq3 < min_unique3_ratio or max3 > max_3gram_count:
return False, "ngram_repetition"
# 5) completeness
if not ends_like_sentence(s):
return False, "incomplete_sentence"
return True, "ok"
SOT_ID = 128000 # Start of Text
EOT_ID = 128009 # End of Text
SOS_ID = 128257 # Start of Speech
EOS_ID = 128258 # End of Speech
SOH_ID = 128259 # Start of Human
EOH_ID = 128260 # End of Human
SOA_ID = 128261 # Start of AI
EOA_ID = 128262 # End of AI
SOT_TOKEN = "<|begin_of_text|>" # Start of Text (128000)
EOT_TOKEN = "<|eot_id|>" # End of Text (128009)
SOS_TOKEN = "<custom_token_1>" # Start of Speech (128257)
EOS_TOKEN = "<custom_token_2>" # End of Speech (128258)
SOH_TOKEN = "<custom_token_3>" # Start of Human (128259)
EOH_TOKEN = "<custom_token_4>" # End of Human (128260)
SOA_TOKEN = "<custom_token_5>" # Start of AI (128261)
EOA_TOKEN = "<custom_token_6>" # End of AI (128262)
tokenizer = AutoTokenizer.from_pretrained(orpheus_model_id)
model = LLM(
model=orpheus_model_id,
gpu_memory_utilization=0.9,
max_model_len=256,
max_num_seqs=BATCH_SIZE,
seed=42,
)
sampling_params = SamplingParams(
temperature=1.0,
top_p=0.9,
repetition_penalty=1.1,
min_p=0.01,
stop_token_ids=[EOT_ID, SOS_ID],
max_tokens=100,
)
INPUT_TEXT = SOH_TOKEN + SOT_TOKEN
prompts = [INPUT_TEXT for _ in range(BATCH_SIZE)]
results = []
for _ in tqdm(range(ITER)):
outputs = model.generate(prompts, sampling_params)
for output in outputs:
generated_text = output.outputs[0].text
finish_reason = output.outputs[0].finish_reason
ok, reason = passes_text_filters(generated_text, finish_reason)
if ok:
results.append({"text": generated_text.strip()})
ds = Dataset.from_list(results)
ds.to_json("output_text.jsonl", orient="records", lines=True)
This yields text snippets to be spoken, e.g.:
[
{
"text": "No, I mean this is the question for you."
},
{
"text": "Is it for a show? You just do that? Yeah, I always tell you this story about my friend, uh, he used to be in radio and he did the whole gig."
},
{
"text": "That the first thing that's, uh, not quite ready yet is going to be this main class, and then you're gonna put the rest of the classes in."
}
]
2) Generating audio tokens
Next, feed each synthesized text to the model using Orpheus-TTS’s training format to obtain audio tokens:
<custom_token_3><|begin_of_text|>{input_text}<|eot_id|><custom_token_4><custom_token_5><custom_token_1>
Where <custom_token_3> = Start of Human, <|begin_of_text|> = Start of Text, <|eot_id|> = End of Text, <custom_token_4> = End of Human, <custom_token_5> = Start of AI, <custom_token_1> = Start of Speech. Here {input_text} is the text from step 1.
Script (vLLM) to generate audio tokens:
Audio-token generation script
import json
import os
from tqdm import tqdm
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
BATCH_SIZE = 200
orpheus_model_id = "canopylabs/orpheus-3b-0.1-pretrained"
SOT_ID = 128000 # Start of Text
EOT_ID = 128009 # End of Text
SOS_ID = 128257 # Start of Speech
EOS_ID = 128258 # End of Speech
SOH_ID = 128259 # Start of Human
EOH_ID = 128260 # End of Human
SOA_ID = 128261 # Start of AI
EOA_ID = 128262 # End of AI
SOT_TOKEN = "<|begin_of_text|>" # Start of Text (128000)
EOT_TOKEN = "<|eot_id|>" # End of Text (128009)
SOS_TOKEN = "<custom_token_1>" # Start of Speech (128257)
EOS_TOKEN = "<custom_token_2>" # End of Speech (128258)
SOH_TOKEN = "<custom_token_3>" # Start of Human (128259)
EOH_TOKEN = "<custom_token_4>" # End of Human (128260)
SOA_TOKEN = "<custom_token_5>" # Start of AI (128261)
EOA_TOKEN = "<custom_token_6>" # End of AI (128262)
tokenizer = AutoTokenizer.from_pretrained(orpheus_model_id)
model = LLM(
model=orpheus_model_id,
gpu_memory_utilization=0.95,
max_model_len=2816,
max_num_seqs=BATCH_SIZE,
max_num_batched_tokens=8192,
seed=42,
)
sampling_params = SamplingParams(
temperature=1.0,
top_p=0.9,
repetition_penalty=1.1,
min_p=0.01,
stop_token_ids=[EOS_ID, EOA_ID],
max_tokens=2560,
)
input_file = "./output_text.jsonl"
output_file = "./output_audio_tokens.jsonl"
# Count already-processed lines (to allow resuming)
if os.path.exists(output_file):
print(f"Scanning existing output file {output_file} ...")
try:
with open(output_file, "r", encoding="utf-8") as f:
num_processed = sum(1 for _ in f)
except Exception as e:
print(f"Error reading output file: {e}")
raise
print(f"Scan complete. Found {num_processed} processed items.")
else:
print(f"Output file {output_file} not found. Creating a new one.")
num_processed = 0
# Load inputs
print(f"Loading input file {input_file} ...")
all_data = []
with open(input_file, "r", encoding="utf-8") as f:
for line in f:
all_data.append(json.loads(line))
print("Loaded.")
# Slice to unprocessed portion
total_items = len(all_data)
if num_processed >= total_items:
print(f"All data ({total_items}) already processed. Exiting.")
unprocessed_data = []
else:
print(f"{num_processed} of {total_items} processed so far.")
unprocessed_data = all_data[num_processed:]
print(f"Processing remaining {len(unprocessed_data)} items...")
# Batch and append to output
if unprocessed_data:
with open(output_file, "a", encoding="utf-8") as f_out:
for i in tqdm(range(0, len(unprocessed_data), BATCH_SIZE), desc="batch processing"):
batch = unprocessed_data[i : min(i + BATCH_SIZE, len(unprocessed_data))]
prompts = []
for row in batch:
text = row["text"]
prompt = f"{SOH_TOKEN}{SOT_TOKEN}{text}{EOT_TOKEN}{EOH_TOKEN}{SOA_TOKEN}{SOS_TOKEN}"
prompts.append(prompt)
outputs = model.generate(prompts, sampling_params)
for item, output in zip(batch, outputs):
generated = output.outputs[0].text
finish_reason = output.outputs[0].finish_reason
result = {
"text": item["text"],
"audio_tokens": generated.strip(),
"finish_reason": finish_reason,
}
f_out.write(json.dumps(result, ensure_ascii=False) + "\n")
f_out.flush()
print("All processing complete.")
This yields text ↔ audio-token pairs like:
[
{
"text": "No, I mean this is the question for you.",
"audio_tokens": "<custom_token_3987><custom_token_4137><custom_token_10650><custom_token_14034> ... <custom_token_21933><custom_token_27976>",
"finish_reason": "stop"
},
{
"text": "Is it for a show? You just do that? Yeah, I always tell you this story about my friend, uh, he used to be in radio and he did the whole gig.",
"audio_tokens": "<custom_token_2856><custom_token_7692><custom_token_9454><custom_token_13859> ... <custom_token_21094><custom_token_28110>",
"finish_reason": "stop"
},
{
"text": "That the first thing that's, uh, not quite ready yet is going to be this main class, and then you're gonna put the rest of the classes in.",
"audio_tokens": "<custom_token_1784><custom_token_5949><custom_token_10319><custom_token_16338> ... <custom_token_21392><custom_token_27976>",
"finish_reason": "stop"
}
]
3) Decoding audio tokens into waveforms
The outputs from step 2 are still discrete audio tokens. Convert them to actual audio using the same codec the model used for training. Orpheus-TTS uses hubertsiuzdak/snac_24khz.
Here’s a minimal script to decode and save audio:
Audio decoding script
import hashlib
import json
import math
import os
import re
import unicodedata
from typing import Iterator, List, Tuple
import soundfile as sf
import torch
from snac import SNAC
from tqdm import tqdm
from transformers import AutoTokenizer
JSONL_IN = "output_audio_tokens.jsonl"
AUDIO_DIR = "dataset/audio"
AUDIO_EXT = ".flac"
BIT_DEPTH = 16
META_OUT = "dataset/metadata.jsonl"
MODEL_ID = "canopylabs/orpheus-3b-0.1-pretrained"
SNAC_MODEL_ID = "hubertsiuzdak/snac_24khz"
SAMPLE_RATE = 24000
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
SUBTYPE = "PCM_24" if BIT_DEPTH == 24 else "PCM_16"
# Orpheus SNAC codebook base ID (aligns with the official notebook)
CODEBOOK_BASE = 128266
# 7 tokens per frame (Orpheus default)
TOKENS_PER_FRAME = 7
# Width of each sub-codebook
CB_WIDTH = 4096
RE_CUSTOM = re.compile(r"<custom_token_\d+>")
snac_model = SNAC.from_pretrained(SNAC_MODEL_ID)
snac_model.to(DEVICE).eval()
def canonicalize_text(s: str) -> str:
# NFKC → collapse whitespace → trim
s = unicodedata.normalize("NFKC", s)
s = re.sub(r"\s+", " ", s).strip()
return s.lower()
def text_hash_blake2s(s: str) -> str:
canon = canonicalize_text(s)
return hashlib.blake2s(canon.encode("utf-8"), digest_size=16).hexdigest() # 128-bit
def chars_per_second(s: str, duration_sec: float) -> Tuple[int, float]:
# count visible (non-space) chars per second
n_vis = len(re.findall(r"\S", s))
d = max(duration_sec, 1e-6)
return n_vis, n_vis / d
def iter_jsonl(path: str) -> Iterator[dict]:
with open(path, "r", encoding="utf-8") as f:
for line in f:
if not line.strip():
continue
yield json.loads(line)
def extract_custom_tokens(s: str) -> List[str]:
# extract <custom_token_xxx> ... one by one
return RE_CUSTOM.findall(s)
def tokens_to_ids(tok, toks: List[str]) -> List[int]:
ids = []
for t in toks:
i = tok.convert_tokens_to_ids(t)
if i is None or i == tok.unk_token_id:
raise ValueError(f"Unknown token in sequence: {t}")
ids.append(i)
return ids
def ids_to_layers(ids: List[int]) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""
Conform to Orpheus's mapping:
- 7 tokens per frame
- subtract CODEBOOK_BASE
- subtract 4096*k for the k-th sub-code to map into [0, 4095]
- return three tensors with shapes [1, T], [1, 2T], [1, 4T]
"""
if len(ids) < TOKENS_PER_FRAME:
raise ValueError("Too few tokens.")
new_len = (len(ids) // TOKENS_PER_FRAME) * TOKENS_PER_FRAME
ids = ids[:new_len]
codes = [i - CODEBOOK_BASE for i in ids]
if any(c < 0 for c in codes):
bad = [c for c in codes if c < 0][:5]
raise ValueError(
f"Found negative codes after base subtraction (e.g., {bad}). "
f"Is CODEBOOK_BASE={CODEBOOK_BASE} correct for your model/tokenizer?"
)
L1, L2, L3 = [], [], []
T = len(codes) // TOKENS_PER_FRAME
for t in range(T):
x0 = codes[7 * t + 0]
x1 = codes[7 * t + 1] - 1 * CB_WIDTH
x2 = codes[7 * t + 2] - 2 * CB_WIDTH
x3 = codes[7 * t + 3] - 3 * CB_WIDTH
x4 = codes[7 * t + 4] - 4 * CB_WIDTH
x5 = codes[7 * t + 5] - 5 * CB_WIDTH
x6 = codes[7 * t + 6] - 6 * CB_WIDTH
for val, name in [
(x0, "x0(L1)"),
(x1, "x1(L2)"),
(x2, "x2(L3)"),
(x3, "x3(L3)"),
(x4, "x4(L2)"),
(x5, "x5(L3)"),
(x6, "x6(L3)"),
]:
if not (0 <= val < CB_WIDTH):
raise ValueError(f"Subcode out of range: {name}={val} at frame {t}")
L1.append(x0)
L2.append(x1)
L3.append(x2)
L3.append(x3)
L2.append(x4)
L3.append(x5)
L3.append(x6)
t1 = torch.tensor(L1, dtype=torch.long, device=DEVICE).unsqueeze(0)
t2 = torch.tensor(L2, dtype=torch.long, device=DEVICE).unsqueeze(0)
t3 = torch.tensor(L3, dtype=torch.long, device=DEVICE).unsqueeze(0)
return t1, t2, t3
def decode_to_audio(snac_model, layers: Tuple[torch.Tensor, torch.Tensor, torch.Tensor]) -> torch.Tensor:
with torch.no_grad():
audio = snac_model.decode(list(layers))
if audio.dim() == 2 and audio.size(0) == 1:
return audio.squeeze(0)
return audio
def ensure_dir(path: str):
os.makedirs(path, exist_ok=True)
# ====== main ======
def main():
tok = AutoTokenizer.from_pretrained(MODEL_ID)
ensure_dir(AUDIO_DIR)
ensure_dir(os.path.dirname(META_OUT))
meta_f = open(META_OUT, "w", encoding="utf-8")
n_ok = n_skip = 0
for idx, ex in enumerate(tqdm(iter_jsonl(JSONL_IN), desc="decoding")):
# process only finish_reason == "stop"
fr = ex.get("finish_reason", "stop")
if fr != "stop":
n_skip += 1
continue
text = ex["text"]
audio_tok_str = ex["audio_tokens"]
try:
toks = extract_custom_tokens(audio_tok_str)
if len(toks) == 0:
raise ValueError("No <custom_token_*> found.")
ids = tokens_to_ids(tok, toks)
t1, t2, t3 = ids_to_layers(ids)
with torch.no_grad():
audio = snac_model.decode([t1, t2, t3]).squeeze(0).to("cpu")
# save audio
fname = f"{idx:09d}{AUDIO_EXT}"
audio_path = os.path.join(AUDIO_DIR, fname)
sf.write(audio_path, audio.numpy().T, SAMPLE_RATE, format="FLAC", subtype=SUBTYPE)
# write metadata
duration = audio.numpy().shape[-1] / SAMPLE_RATE
num_chars, cps = chars_per_second(text, duration)
item = {
"id": f"{idx:09d}",
"text": text,
"text_hash": text_hash_blake2s(text),
"audio_path": audio_path,
"n_audio_tokens": len(ids),
"frames": len(ids) // TOKENS_PER_FRAME,
"sr": SAMPLE_RATE,
"duration_sec": round(duration, 3),
"num_chars": num_chars,
"cps": round(cps, 3),
}
meta_f.write(json.dumps(item, ensure_ascii=False) + "\n")
n_ok += 1
except Exception as e:
print(f"[skip #{idx}] {e}")
n_skip += 1
continue
meta_f.close()
print(f"done. ok={n_ok}, skip={n_skip}")
if __name__ == "__main__":
main()
4) Filtering
Apply any filtering you need. In this dataset, I applied:
- Exact-match deduplication by text hash.
- Remove top and bottom 10% by CPS (Characters Per Second).
- Transcribe with openai/whisper-large-v3, compute WER/CER vs. source text, and keep samples where
WER ≤ 0.15andCER ≤ 0.05. - Clip-rate filtering (exclude if proportion of
abs(x) ≥ 0.999exceeds 0.05%). - DC offset filtering (exclude if
abs(mean(x)) > 3e-4). - Score with DNSMOS and drop the bottom 15%.
This is just one recipe; add or adjust filters to taste.
The final dataset lives here:
https://huggingface.co/datasets/Aratako/Magpie-Speech-Orpheus-125k
Conclusion
I showed how to adapt Magpie—an LLM instruction-synthesis method—to an LLM-based TTS model to create a synthetic speech dataset. I haven’t yet validated how useful this dataset is in downstream training, but I find it exciting that LLM-style data generation can bootstrap speech datasets. I expect other LLM-era techniques could be applied similarly to broaden the variety and coverage of synthetic speech corpora.