
feihu.hf
commited on
Commit
·
da58b03
1
Parent(s):
c38cd4a
update readme
Browse files- README.md +7 -1
- figures/benchmark.jpg +0 -0
README.md
CHANGED
|
@@ -19,6 +19,10 @@ tags:
|
|
| 19 |
|
| 20 |
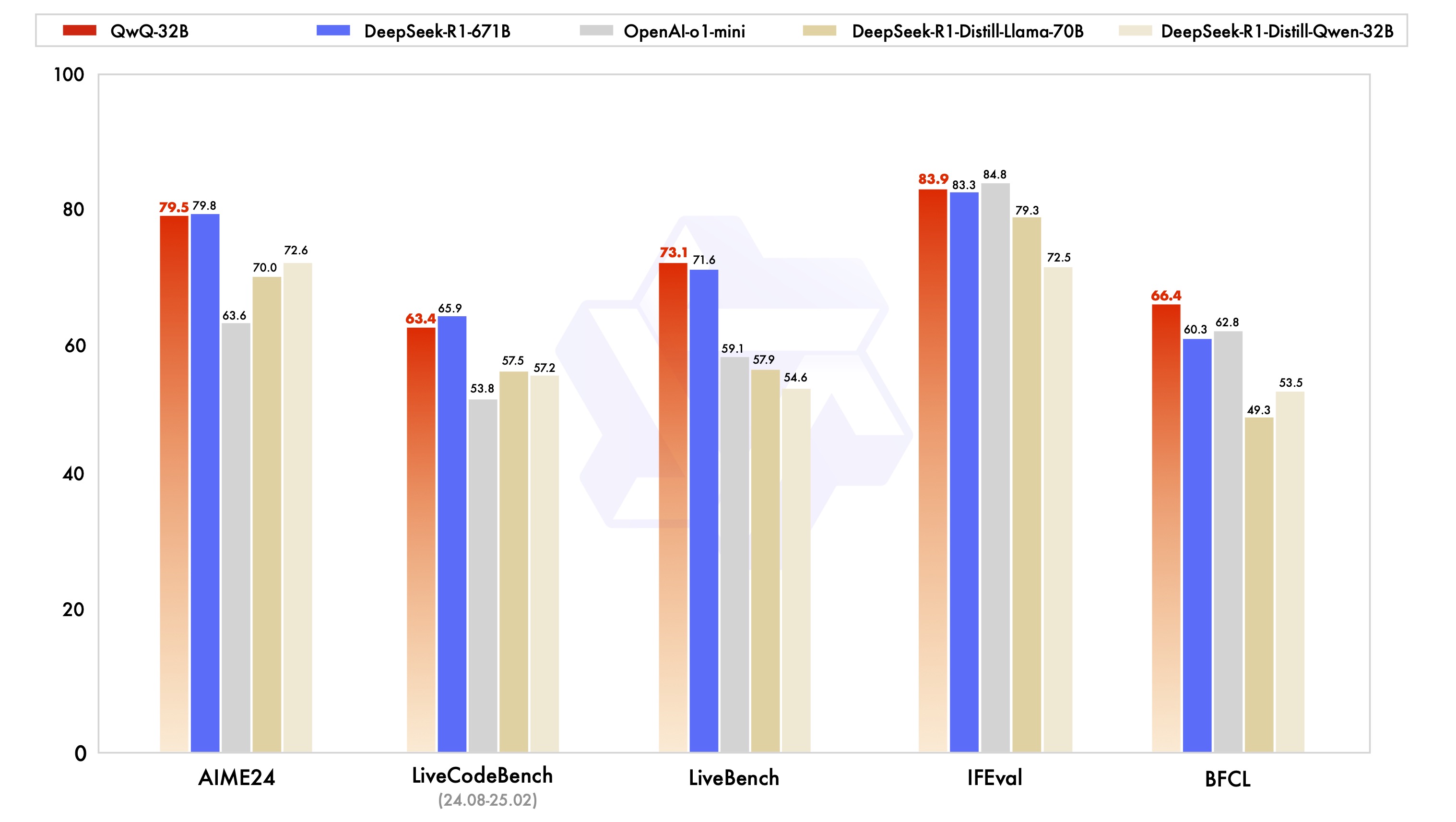
QwQ is the reasoning model of the Qwen series. Compared with conventional instruction-tuned models, QwQ, which is capable of thinking and reasoning, can achieve significantly enhanced performance in downstream tasks, especially hard problems. QwQ-32B is the medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini.
|
| 21 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
**This repo contains the QwQ 32B model in the GGUF Format**, which has the following features:
|
| 23 |
- Type: Causal Language Models
|
| 24 |
- Training Stage: Pretraining & Post-training (Supervised Finetuning and Reinforcement Learning)
|
|
@@ -32,6 +36,8 @@ QwQ is the reasoning model of the Qwen series. Compared with conventional instru
|
|
| 32 |
|
| 33 |
**Note:** For the best experience, please review the [usage guidelines](#usage-guidelines) before deploying QwQ models.
|
| 34 |
|
|
|
|
|
|
|
| 35 |
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwq-32b/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
|
| 36 |
|
| 37 |
## Requirements
|
|
@@ -103,7 +109,7 @@ If you find our work helpful, feel free to give us a cite.
|
|
| 103 |
|
| 104 |
```
|
| 105 |
@misc{qwq32b,
|
| 106 |
-
title = {
|
| 107 |
url = {https://qwenlm.github.io/blog/qwq-32b/},
|
| 108 |
author = {Qwen Team},
|
| 109 |
month = {March},
|
|
|
|
| 19 |
|
| 20 |
QwQ is the reasoning model of the Qwen series. Compared with conventional instruction-tuned models, QwQ, which is capable of thinking and reasoning, can achieve significantly enhanced performance in downstream tasks, especially hard problems. QwQ-32B is the medium-sized reasoning model, which is capable of achieving competitive performance against state-of-the-art reasoning models, e.g., DeepSeek-R1, o1-mini.
|
| 21 |
|
| 22 |
+
<p align="center">
|
| 23 |
+
<img width="100%" src="figures/benchmark.jpg">
|
| 24 |
+
</p>
|
| 25 |
+
|
| 26 |
**This repo contains the QwQ 32B model in the GGUF Format**, which has the following features:
|
| 27 |
- Type: Causal Language Models
|
| 28 |
- Training Stage: Pretraining & Post-training (Supervised Finetuning and Reinforcement Learning)
|
|
|
|
| 36 |
|
| 37 |
**Note:** For the best experience, please review the [usage guidelines](#usage-guidelines) before deploying QwQ models.
|
| 38 |
|
| 39 |
+
You can try our [demo](https://huggingface.co/spaces/Qwen/QwQ-32B-Demo) or access QwQ models via [QwenChat](https://chat.qwen.ai).
|
| 40 |
+
|
| 41 |
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwq-32b/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
|
| 42 |
|
| 43 |
## Requirements
|
|
|
|
| 109 |
|
| 110 |
```
|
| 111 |
@misc{qwq32b,
|
| 112 |
+
title = {QwQ-32B: The Power of Scaling RL},
|
| 113 |
url = {https://qwenlm.github.io/blog/qwq-32b/},
|
| 114 |
author = {Qwen Team},
|
| 115 |
month = {March},
|
figures/benchmark.jpg
ADDED
|