

Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama3.2
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
datasets:
|
| 6 |
+
- PJMixers-Dev/HailMary-v0.1-KTO
|
| 7 |
+
base_model:
|
| 8 |
+
- PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B
|
| 9 |
+
---
|
| 10 |
+
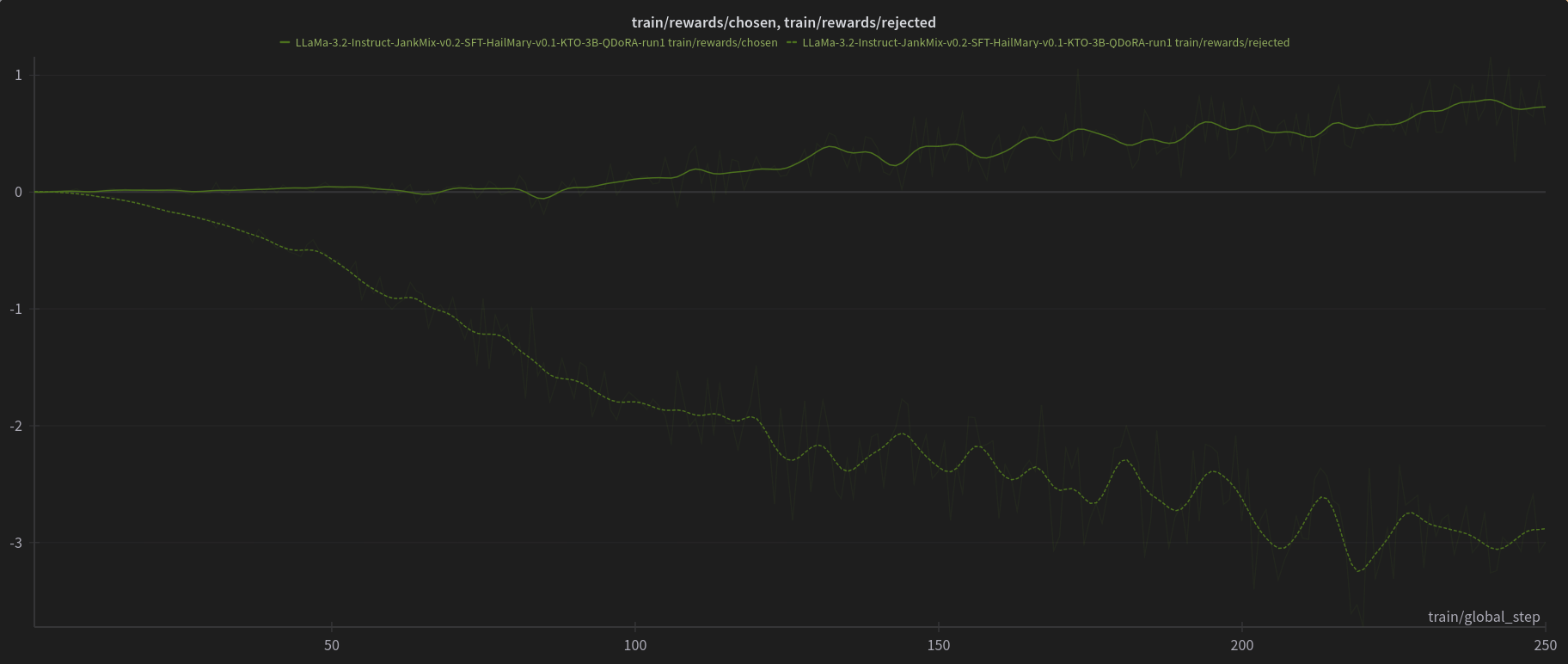
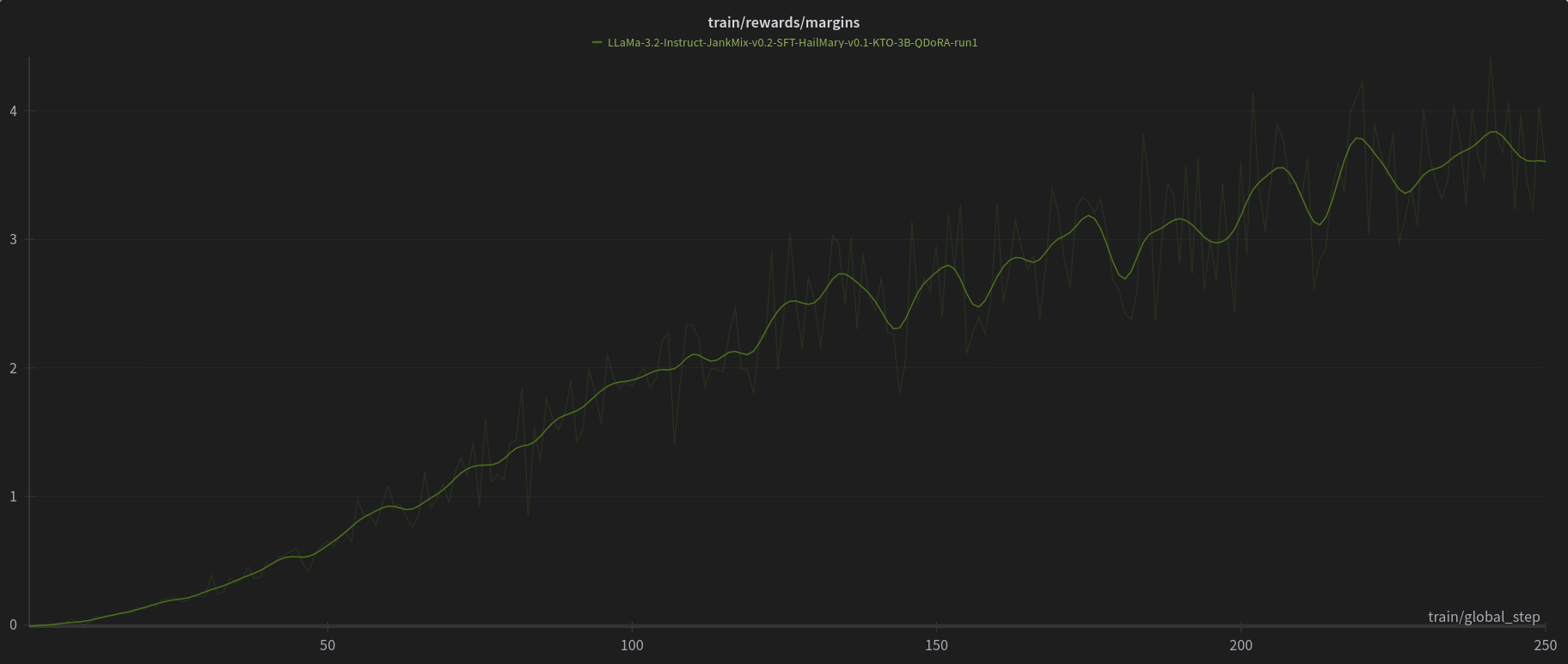
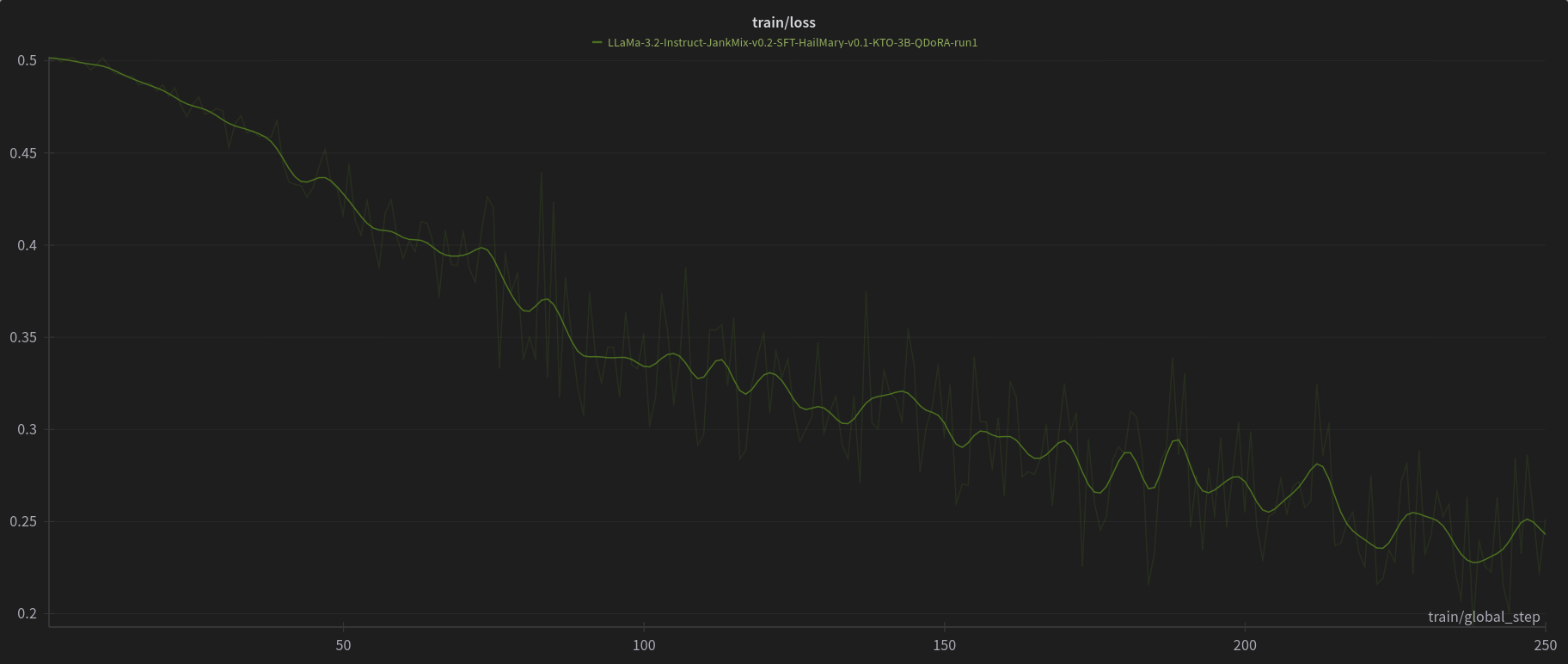
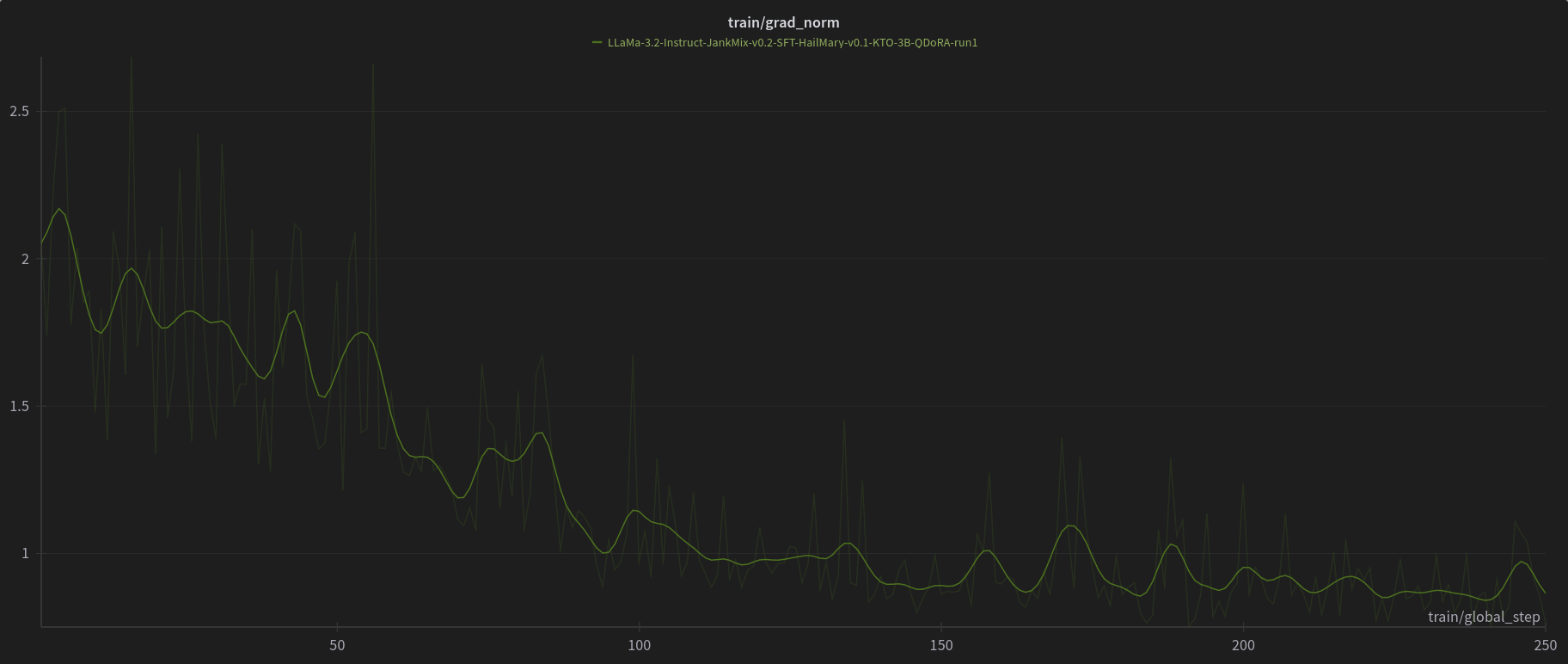
[PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B](https://huggingface.co/PJMixers-Dev/LLaMa-3.2-Instruct-JankMix-v0.2-SFT-3B) was further trained using KTO (with `apo_zero_unpaired` loss type) using a mix of instruct, RP, and storygen datasets. I created rejected samples by using the SFT with bad settings (including logit bias) for every model turn.
|
| 11 |
+
|
| 12 |
+
The model was only trained at `max_length=6144`, and is nowhere near a full epoch as it eventually crashed. So think of this like a test of a test.
|
| 13 |
+
|
| 14 |
+
---
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|