---
license: apache-2.0
pipeline_tag: text-to-speech
---
This repository contains the model as described in [LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM](https://hf.co/papers/2503.04724).
For more information, check out the project page at https://mbzuai-oryx.github.io/LLMVoX/ and the code at https://github.com/mbzuai-oryx/LLMVoX.
# LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM
**Authors:**
**[Sambal Shikar](https://github.com/mbzuai-oryx/LLMVoX?tab=readme-ov-file)**, **[Mohammed Irfan K](https://scholar.google.com/citations?user=GJp0keYAAAAJ&hl=en)**, **[Sahal Shaji Mullappilly](https://scholar.google.com/citations?user=LJWxVpUAAAAJ&hl=en)**, **[Fahad Khan](https://sites.google.com/view/fahadkhans/home)**, **[Jean Lahoud](https://scholar.google.com/citations?user=LsivLPoAAAAJ&hl=en)**, **[Rao Muhammad Anwer](https://scholar.google.com/citations?hl=en&authuser=1&user=_KlvMVoAAAAJ)**, **[Salman Khan](https://salman-h-khan.github.io/)**, **[Hisham Cholakkal](https://scholar.google.com/citations?hl=en&user=bZ3YBRcAAAAJ)**
**Mohamed Bin Zayed University of Artificial Intelligence (MBZUAI), UAE**

## Overview
LLMVoX is a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming Text-to-Speech (TTS) system designed to convert text outputs from Large Language Models into high-fidelity streaming speech with low latency.
Key features:
- 🚀 **Lightweight & Fast**: Only 30M parameters with end-to-end latency as low as 300ms
- 🔌 **LLM-Agnostic**: Works with any LLM and Vision-Language Model without fine-tuning
- 🌊 **Multi-Queue Streaming**: Enables continuous, low-latency speech generation
- 🌐 **Multilingual Support**: Adaptable to new languages with dataset adaptation
## Quick Start
### Installation
```bash
# Requirements: CUDA 11.7+, Flash Attention 2.0+ compatible GPU
git clone https://github.com/mbzuai-oryx/LLMVoX.git
cd LLMVoX
conda create -n llmvox python=3.9
conda activate llmvox
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install flash-attn --no-build-isolation
pip install -r requirements.txt
# Download checkpoints from Hugging Face
# https://huggingface.co/MBZUAI/LLMVoX/tree/main
mkdir -p CHECKPOINTS
# Download wavtokenizer_large_speech_320_24k.ckpt and ckpt_english_tiny.pt
```
### Voice Chat
```bash
# Basic usage
python streaming_server.py --chat_type voice --llm_checkpoint "meta-llama/Llama-3.1-8B-Instruct"
# With multiple GPUs
python streaming_server.py --chat_type voice --llm_checkpoint "meta-llama/Llama-3.1-8B-Instruct" \
--llm_device "cuda:0" --tts_device_1 1 --tts_device_2 2
# Balance latency/quality
python streaming_server.py --chat_type voice --llm_checkpoint "meta-llama/Llama-3.1-8B-Instruct" \
--initial_dump_size_1 10 --initial_dump_size_2 160 --max_dump_size 1280
```
### Text Chat & Visual Speech
```bash
# Text-to-Speech
python streaming_server.py --chat_type text --llm_checkpoint "meta-llama/Llama-3.1-8B-Instruct"
# Visual Speech (Speech + Image → Speech)
python streaming_server.py --chat_type visual_speech --llm_checkpoint "Qwen/Qwen2.5-VL-7B-Instruct" \
--eos_token "<|im_end|>"
# Multimodal (support for models like Phi-4)
python streaming_server.py --chat_type multimodal --llm_checkpoint "microsoft/Phi-4-multimodal-instruct" \
--eos_token "<|end|>"
```
## API Reference
| Endpoint | Purpose | Required Parameters |
|----------|---------|---------------------|
| `/tts` | Text-to-speech | `text`: String to convert |
| `/voicechat` | Voice conversations | `audio_base64`, `source_language`, `target_language` |
| `/multimodalchat` | Voice + multiple images | `audio_base64`, `image_list` |
| `/vlmschat` | Voice + single image | `audio_base64`, `image_base64`, `source_language`, `target_language` |
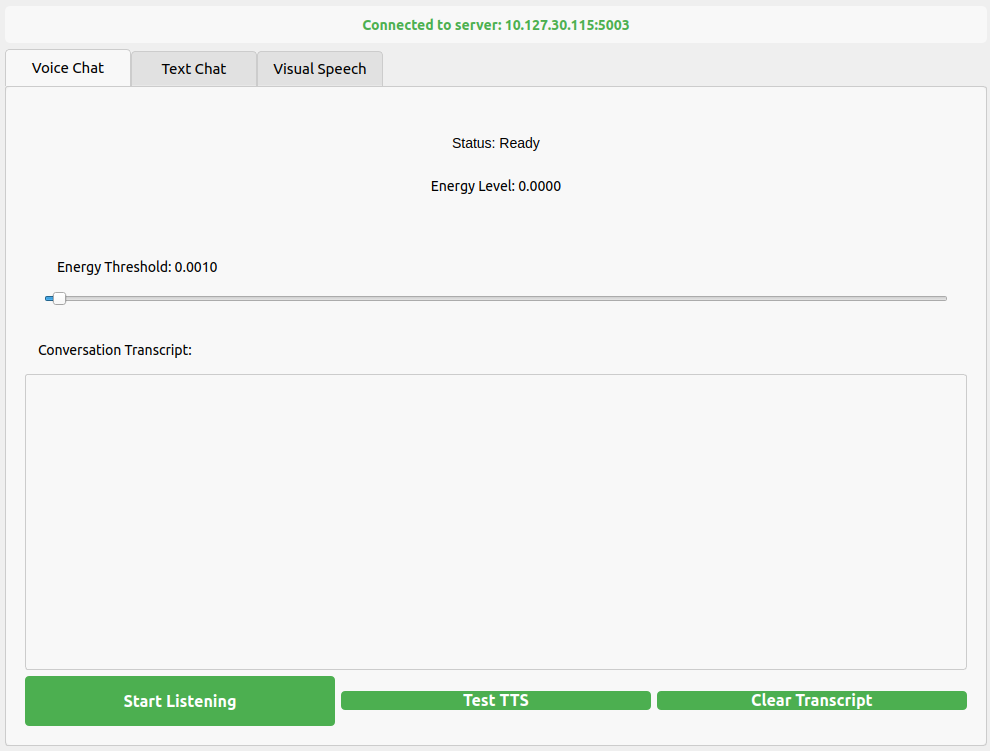
## Local UI Demo
```bash
# Start server
python streaming_server.py --chat_type voice --llm_checkpoint "meta-llama/Llama-3.1-8B-Instruct" --api_port PORT
# Launch UI
python run_ui.py --ip STREAMING_SERVER_IP --port PORT
```
## Citation
```bibtex
@article{shikhar2025llmvox,
title={LLMVoX: Autoregressive Streaming Text-to-Speech Model for Any LLM},
author={Shikhar, Sambal and Kurpath, Mohammed Irfan and Mullappilly, Sahal Shaji and Lahoud, Jean and Khan, Fahad and Anwer, Rao Muhammad and Khan, Salman and Cholakkal, Hisham},
journal={arXiv preprint arXiv:2503.04724},
year={2025}
}
```
## Acknowledgments
- [Andrej Karpathy's NanoGPT](https://github.com/karpathy/nanoGPT)
- [WavTokenizer](https://github.com/jishengpeng/WavTokenizer)
- [Whisper](https://github.com/openai/whisper)
- [Neural G2P](https://github.com/lingjzhu/CharsiuG2P)
## License
This project is licensed under the MIT License - see the [LICENSE](LICENSE) file for details.