
Upload 51 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +4 -0
- .gitignore +12 -0
- .vscode/launch.json +21 -0
- Architecture.png +3 -0
- LICENSE +21 -0
- README.md +106 -0
- config/__pycache__/config.cpython-310.pyc +0 -0
- config/__pycache__/config.cpython-311.pyc +0 -0
- config/config.py +81 -0
- constants.py +64 -0
- data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_10_TLOB_seed_42.ckpt +3 -0
- data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_1_TLOB_seed_42.ckpt +3 -0
- data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_2_TLOB_seed_42.ckpt +3 -0
- data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_5_TLOB_seed_42.ckpt +3 -0
- fI-2010.png +3 -0
- main.py +75 -0
- models/__pycache__/bin.cpython-310.pyc +0 -0
- models/__pycache__/bin.cpython-311.pyc +0 -0
- models/__pycache__/binctabl.cpython-311.pyc +0 -0
- models/__pycache__/deeplob.cpython-311.pyc +0 -0
- models/__pycache__/engine.cpython-310.pyc +0 -0
- models/__pycache__/engine.cpython-311.pyc +0 -0
- models/__pycache__/mlp.cpython-310.pyc +0 -0
- models/__pycache__/mlp.cpython-311.pyc +0 -0
- models/__pycache__/transformer.cpython-311.pyc +0 -0
- models/bin.py +87 -0
- models/binctabl.py +129 -0
- models/deeplob.py +102 -0
- models/engine.py +294 -0
- models/mlplob.py +83 -0
- models/tlob.py +177 -0
- preprocessing/__pycache__/dataset.cpython-310.pyc +0 -0
- preprocessing/__pycache__/dataset.cpython-311.pyc +0 -0
- preprocessing/__pycache__/fi_2010.cpython-310.pyc +0 -0
- preprocessing/__pycache__/fi_2010.cpython-311.pyc +0 -0
- preprocessing/__pycache__/lobster.cpython-310.pyc +0 -0
- preprocessing/__pycache__/lobster.cpython-311.pyc +0 -0
- preprocessing/dataset.py +87 -0
- preprocessing/fi_2010.py +53 -0
- preprocessing/lobster.py +324 -0
- requirements.txt +19 -0
- run.py +434 -0
- tslaintc.png +0 -0
- utils/__pycache__/utils_data.cpython-311.pyc +0 -0
- utils/__pycache__/utils_model.cpython-310.pyc +0 -0
- utils/__pycache__/utils_model.cpython-311.pyc +0 -0
- utils/utils_data.py +238 -0
- utils/utils_model.py +18 -0
- visualizations/__pycache__/attentions.cpython-311.pyc +0 -0
- visualizations/attentions.py +30 -0
.gitattributes
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
data/checkpoints/TLOB/HuggingFace/*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
Architecture.png filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
fI-2010.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
wandb
|
| 2 |
+
outputs
|
| 3 |
+
.hydra
|
| 4 |
+
__pycache__
|
| 5 |
+
lightning_logs
|
| 6 |
+
data/d*
|
| 7 |
+
data/I*
|
| 8 |
+
data/T*
|
| 9 |
+
data/F*
|
| 10 |
+
preprocessing
|
| 11 |
+
env
|
| 12 |
+
data/checkpoints/TLOB/v*
|
.vscode/launch.json
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
// Use IntelliSense to learn about possible attributes.
|
| 3 |
+
// Hover to view descriptions of existing attributes.
|
| 4 |
+
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
|
| 5 |
+
"version": "0.2.0",
|
| 6 |
+
"configurations": [
|
| 7 |
+
|
| 8 |
+
{
|
| 9 |
+
"name": "Python Debugger: Current File with Arguments",
|
| 10 |
+
"type": "debugpy",
|
| 11 |
+
"request": "launch",
|
| 12 |
+
"program": "${file}",
|
| 13 |
+
"console": "integratedTerminal",
|
| 14 |
+
"args": [
|
| 15 |
+
"+model=mlplob",
|
| 16 |
+
"hydra.job.chdir=False",
|
| 17 |
+
"hydra.run.dir=.",
|
| 18 |
+
]
|
| 19 |
+
}
|
| 20 |
+
]
|
| 21 |
+
}
|
Architecture.png
ADDED
|
Git LFS Details
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2025 Leonardo Berti
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# TLOB: A Novel Transformer Model with Dual Attention for Stock Price Trend Prediction with Limit Order Book Data
|
| 2 |
+
This is the official repository for the paper TLOB: A Novel Transformer Model with Dual Attention for Stock Price Trend Prediction with Limit Order Book Data.
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
## Abstract
|
| 6 |
+
Stock Price Trend Prediction (SPTP) based on Limit Order Book
|
| 7 |
+
(LOB) data is a fundamental challenge in financial markets. Despite advances in deep learning, existing models fail to generalize across different market conditions and struggle to predict short-term trends reliably. Surprisingly, by adapting a simple MLP-based architecture to LOB, we show that we surpass SoTA performance, thus challenging the necessity of complex architectures. Unlike past work that shows robustness issues, we propose TLOB, a transformer-based model that uses a dual attention mechanism to capture spatial and temporal dependencies in LOB data. This allows it to adaptively focus on the market microstructure, making it particularly effective for longer-horizon predictions and volatile market conditions. We also introduce a new labeling method that improves on previous ones, removing the horizon bias. We evaluate LOB’s effectiveness using the established FI-2010 benchmark, which exceeds the state-of-the-art by an average of 3.7 F1-score(%). Additionally, TLOB shows improvements on Tesla and Intel with a 1.3 and 7.7 increase in F1-score(%), respectively. Additionally, we empirically show how stock price predictability has declined over time (-6.68 absolute points in F1-score(%)), highlighting the growing market efficiencies. Predictability must be considered in relation to transaction costs, so we experimented with defining trends using an average spread, reflecting the primary transaction cost. The resulting performance deterioration underscores the complexity of translating trend classification into profitable trading strategies. We argue that our work provides new insights into the evolving landscape of stock price trend prediction and sets a strong foundation for future advancements in financial AI.
|
| 8 |
+
|
| 9 |
+
# Getting Started
|
| 10 |
+
These instructions will get you a copy of the project up and running on your local machine for development and reproducibility purposes.
|
| 11 |
+
|
| 12 |
+
## Prerequisities
|
| 13 |
+
This project requires Python and pip. If you don't have them installed, please do so first. It is possible to do it using conda, but in that case, you are on your own.
|
| 14 |
+
|
| 15 |
+
## Installing
|
| 16 |
+
To set up the environment for this project, follow these steps:
|
| 17 |
+
|
| 18 |
+
1. Clone the repository:
|
| 19 |
+
```sh
|
| 20 |
+
git clone https://github.com/LeonardoBerti00/TLOB.git
|
| 21 |
+
```
|
| 22 |
+
2. Navigate to the project directory
|
| 23 |
+
3. Create a virtual environment:
|
| 24 |
+
```sh
|
| 25 |
+
python -m venv env
|
| 26 |
+
```
|
| 27 |
+
4. Activate the new Conda environment:
|
| 28 |
+
```sh
|
| 29 |
+
env\Scripts\activate
|
| 30 |
+
```
|
| 31 |
+
5. Download the necessary packages:
|
| 32 |
+
```sh
|
| 33 |
+
pip install -r requirements.txt
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
# Reproduce the results
|
| 37 |
+
To reproduce the results follow the following steps:
|
| 38 |
+
|
| 39 |
+
1. Download the dataset from the [official website](https://etsin.fairdata.fi/dataset/73eb48d7-4dbc-4a10-a52a-da745b47a649/data).
|
| 40 |
+
2. Unzip the data
|
| 41 |
+
3. Create a folder FI-2010 inside your repository
|
| 42 |
+
4. Copy these four files in the folder: "Test_Dst_NoAuction_ZScore_CF_7.txt", "Test_Dst_NoAuction_ZScore_CF_8.txt", "Test_Dst_NoAuction_ZScore_CF_9", "Train_Dst_NoAuction_ZScore_CF_7.txt" you can delete the other files.
|
| 43 |
+
5. In data/checkpoints/TLOB/HuggingFace/ you can find the four checkpoint for FI-2010, the checkpoints for TSLA and INTC did not fit in the free GitHub repository size. If you need also the other checkpoints you can contact me.
|
| 44 |
+
6. Finally, inside the config file, you need to set Dataset to FI-2010, set the horizons to 1, 2, 5, or 10, then set the checkpoint_reference variable to the path of the checkpoint with the same horizon, finally set the type to EVALUATION.
|
| 45 |
+
7. Now run:
|
| 46 |
+
```sh
|
| 47 |
+
python main.py +model=tlob hydra.job.chdir=False
|
| 48 |
+
```
|
| 49 |
+
Note that the horizons in the paper are an order of magnitude higher because in the paper the value represent the horizons before the sampling process of the dataset. In fact, the dataset is sampled every 10 events.
|
| 50 |
+
|
| 51 |
+
# Training
|
| 52 |
+
If your objective is to train a TLOB or MLPLOB model or implement your model you should follow those steps.
|
| 53 |
+
|
| 54 |
+
## Data
|
| 55 |
+
If you have some LOBSTER data you can follow those steps:
|
| 56 |
+
1. The format of the data should be the same of LOBSTER: f"{year}-{month}-{day}_34200000_57600000_{type}" and the data should be saved in f"data/{stock_name}/{stock_name}_{year}-{start_month}-{start_day}_{year}-{end_month}-{end_day}". Type can be or message or orderbook.
|
| 57 |
+
2. Inside the config file, you need to set the name of the training stock and the testing stocks, and also the dataset to LOBSTER. Currently you can add only one for the training but several for testing.
|
| 58 |
+
3. You need to start the pre-processing step, to do so set config.is_data_preprocessed to False and run python main.py
|
| 59 |
+
|
| 60 |
+
Otherwise, if you want to train and test the model with the Benchmark dataset FI-2010 you can follow these steps:
|
| 61 |
+
1. Download the dataset from the [official website](https://etsin.fairdata.fi/dataset/73eb48d7-4dbc-4a10-a52a-da745b47a649/data).
|
| 62 |
+
2. Unzip the data
|
| 63 |
+
3. Create a folder FI-2010 inside your repository
|
| 64 |
+
4. Copy these four files in the folder: "Test_Dst_NoAuction_ZScore_CF_7.txt", "Test_Dst_NoAuction_ZScore_CF_8.txt", "Test_Dst_NoAuction_ZScore_CF_9", "Train_Dst_NoAuction_ZScore_CF_7.txt" you can delete the other files.
|
| 65 |
+
5. Finally, inside the config file, you need to set Dataset to FI-2010 and set the horizons to 1, 2, 5, or 10.
|
| 66 |
+
Note that the horizons in the paper are an order of magnitude higher because in the paper the value represent the horizons before the sampling process of the dataset. In fact, the dataset is sampled every 10 events.
|
| 67 |
+
|
| 68 |
+
## Training a TLOB, MLPLOB, DeepLOB or BiNCTABL Model
|
| 69 |
+
To train a TLOB, MLPLOB, DeepLOB or BiNCTABL Model, you need to set the type variable in the config file to TRAINING, then run this command:
|
| 70 |
+
```sh
|
| 71 |
+
python main.py +model={model_name} hydra.job.chdir=False
|
| 72 |
+
```
|
| 73 |
+
you can see all the model names in the config file.
|
| 74 |
+
|
| 75 |
+
## Implementing and Training a new model
|
| 76 |
+
To implement a new model, follow these steps:
|
| 77 |
+
1. Implement your model class in the models/ directory. Your model class will take in input an input of dimension [batch_size, seq_len, num_features], and should output a tensor of dimension [batch_size, 3].
|
| 78 |
+
2. add your model to pick_model in utils_models.
|
| 79 |
+
3. Update the config file to include your model and its hyperparameters. If you are using the FI-2010 dataset, It is suggested to set the hidden dim to 40 and the hp all_features to false if you want to use only the LOB as input or if you want to use the LOB and market features the hidden dim should be 144 and all features true. If you are using LOBSTER data, it is suggested to set the hidden dim to 46 and all features to true to use LOB and orders, while if you want to use only the LOB set all features to False.
|
| 80 |
+
4. Add your model with cs.store, similar to the other models
|
| 81 |
+
5. Run the training script:
|
| 82 |
+
```sh
|
| 83 |
+
python main.py +model={your_model_name} hydra.job.chdir=False
|
| 84 |
+
```
|
| 85 |
+
6. You can set whatever configuration using the hydra style of prompt.
|
| 86 |
+
7. A checkpoint will be saved in data/checkpoints/
|
| 87 |
+
|
| 88 |
+
Optionally you can also log the run with wandb or run a sweep, changing the config experiment options.
|
| 89 |
+
|
| 90 |
+
# Results
|
| 91 |
+
MLPLOB and TLOB outperform all the other SoTA deep learning models for Stock Price Trend Prediction with LOB data for both datasets, FI-2010 benchmark and TSLA-INTC.
|
| 92 |
+

|
| 93 |
+

|
| 94 |
+
|
| 95 |
+
# Citation
|
| 96 |
+
```sh
|
| 97 |
+
@misc{berti2025tlobnoveltransformermodel,
|
| 98 |
+
title={TLOB: A Novel Transformer Model with Dual Attention for Stock Price Trend Prediction with Limit Order Book Data},
|
| 99 |
+
author={Leonardo Berti and Gjergji Kasneci},
|
| 100 |
+
year={2025},
|
| 101 |
+
eprint={2502.15757},
|
| 102 |
+
archivePrefix={arXiv},
|
| 103 |
+
primaryClass={q-fin.ST},
|
| 104 |
+
url={https://arxiv.org/abs/2502.15757},
|
| 105 |
+
}
|
| 106 |
+
```
|
config/__pycache__/config.cpython-310.pyc
ADDED
|
Binary file (4.55 kB). View file
|
|
|
config/__pycache__/config.cpython-311.pyc
ADDED
|
Binary file (7.64 kB). View file
|
|
|
config/config.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List
|
| 2 |
+
from hydra.core.config_store import ConfigStore
|
| 3 |
+
from dataclasses import dataclass, field
|
| 4 |
+
from constants import Dataset, ModelType
|
| 5 |
+
from omegaconf import MISSING, OmegaConf
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
@dataclass
|
| 9 |
+
class Model:
|
| 10 |
+
hyperparameters_fixed: dict = MISSING
|
| 11 |
+
hyperparameters_sweep: dict = MISSING
|
| 12 |
+
type: ModelType = MISSING
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@dataclass
|
| 16 |
+
class MLPLOB(Model):
|
| 17 |
+
hyperparameters_fixed: dict = field(default_factory=lambda: {"num_layers": 3, "hidden_dim": 144, "lr": 0.0003, "seq_size": 384, "all_features": True})
|
| 18 |
+
hyperparameters_sweep: dict = field(default_factory=lambda: {"num_layers": [3, 6], "hidden_dim": [128], "lr": [0.0003], "seq_size": [384]})
|
| 19 |
+
type: ModelType = ModelType.MLPLOB
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
@dataclass
|
| 23 |
+
class TLOB(Model):
|
| 24 |
+
hyperparameters_fixed: dict = field(default_factory=lambda: {"num_layers": 4, "hidden_dim": 144, "num_heads": 1, "is_sin_emb": True, "lr": 0.0001, "seq_size": 128, "all_features": True})
|
| 25 |
+
hyperparameters_sweep: dict = field(default_factory=lambda: {"num_layers": [4, 6], "hidden_dim": [128, 256], "num_heads": [1], "is_sin_emb": [True], "lr": [0.0001], "seq_size": [128]})
|
| 26 |
+
type: ModelType = ModelType.TLOB
|
| 27 |
+
|
| 28 |
+
@dataclass
|
| 29 |
+
class BiNCTABL(Model):
|
| 30 |
+
hyperparameters_fixed: dict = field(default_factory=lambda: {"lr": 0.001, "seq_size": 10, "all_features": False})
|
| 31 |
+
hyperparameters_sweep: dict = field(default_factory=lambda: {"lr": [0.001], "seq_size": [10]})
|
| 32 |
+
type: ModelType = ModelType.BINCTABL
|
| 33 |
+
|
| 34 |
+
@dataclass
|
| 35 |
+
class DeepLOB(Model):
|
| 36 |
+
hyperparameters_fixed: dict = field(default_factory=lambda: {"lr": 0.01, "seq_size": 100, "all_features": False})
|
| 37 |
+
hyperparameters_sweep: dict = field(default_factory=lambda: {"lr": [0.01], "seq_size": [100]})
|
| 38 |
+
type: ModelType = ModelType.DEEPLOB
|
| 39 |
+
|
| 40 |
+
@dataclass
|
| 41 |
+
class Experiment:
|
| 42 |
+
is_data_preprocessed: bool = True
|
| 43 |
+
is_wandb: bool = False
|
| 44 |
+
is_sweep: bool = False
|
| 45 |
+
type: list = field(default_factory=lambda: ["EVALUATION"])
|
| 46 |
+
is_debug: bool = False
|
| 47 |
+
checkpoint_reference: str = "data/checkpoints/TLOB/val_loss=0.188_epoch=4_FI-2010_seq_size_128_horizon_10_nu_4_hi_144_nu_1_is_True_lr_0.0001_se_128_al_True_ty_TLOB_seed_42.ckpt"
|
| 48 |
+
dataset_type: Dataset = Dataset.FI_2010
|
| 49 |
+
sampling_type: str = "quantity" #time or quantity
|
| 50 |
+
sampling_time: str = "" #seconds
|
| 51 |
+
sampling_quantity: int = 500
|
| 52 |
+
training_stocks: list = field(default_factory=lambda: ["INTC"])
|
| 53 |
+
testing_stocks: list = field(default_factory=lambda: ["INTC"])
|
| 54 |
+
seed: int = 22
|
| 55 |
+
horizon: int = 5
|
| 56 |
+
max_epochs: int = 10
|
| 57 |
+
if dataset_type == Dataset.FI_2010:
|
| 58 |
+
batch_size: int = 32
|
| 59 |
+
else:
|
| 60 |
+
batch_size: int = 128
|
| 61 |
+
filename_ckpt: str = "model.ckpt"
|
| 62 |
+
optimizer: str = "Adam"
|
| 63 |
+
|
| 64 |
+
defaults = [Model, Experiment]
|
| 65 |
+
|
| 66 |
+
@dataclass
|
| 67 |
+
class Config:
|
| 68 |
+
model: Model
|
| 69 |
+
experiment: Experiment = field(default_factory=Experiment)
|
| 70 |
+
defaults: List = field(default_factory=lambda: [
|
| 71 |
+
{"hydra/job_logging": "disabled"},
|
| 72 |
+
{"hydra/hydra_logging": "disabled"},
|
| 73 |
+
"_self_"
|
| 74 |
+
])
|
| 75 |
+
|
| 76 |
+
cs = ConfigStore.instance()
|
| 77 |
+
cs.store(name="config", node=Config)
|
| 78 |
+
cs.store(group="model", name="mlplob", node=MLPLOB)
|
| 79 |
+
cs.store(group="model", name="tlob", node=TLOB)
|
| 80 |
+
cs.store(group="model", name="binctabl", node=BiNCTABL)
|
| 81 |
+
cs.store(group="model", name="deeplob", node=DeepLOB)
|
constants.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from enum import Enum
|
| 3 |
+
|
| 4 |
+
class Dataset(Enum):
|
| 5 |
+
LOBSTER = "LOBSTER"
|
| 6 |
+
FI_2010 = "FI-2010"
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class ModelType(Enum):
|
| 10 |
+
MLPLOB = "MLPLOB"
|
| 11 |
+
TLOB = "TLOB"
|
| 12 |
+
BINCTABL = "BINCTABL"
|
| 13 |
+
DEEPLOB = "DEEPLOB"
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# for 15 days of TSLA
|
| 18 |
+
TSLA_LOB_MEAN_SIZE_10 = 165.44670902537212
|
| 19 |
+
TSLA_LOB_STD_SIZE_10 = 481.7127061897184
|
| 20 |
+
TSLA_LOB_MEAN_PRICE_10 = 20180.439318660694
|
| 21 |
+
TSLA_LOB_STD_PRICE_10 = 814.8782058033195
|
| 22 |
+
|
| 23 |
+
TSLA_EVENT_MEAN_SIZE = 88.09459295373463
|
| 24 |
+
TSLA_EVENT_STD_SIZE = 86.55913199110894
|
| 25 |
+
TSLA_EVENT_MEAN_PRICE = 20178.610720500274
|
| 26 |
+
TSLA_EVENT_STD_PRICE = 813.8188032145645
|
| 27 |
+
TSLA_EVENT_MEAN_TIME = 0.08644932804905886
|
| 28 |
+
TSLA_EVENT_STD_TIME = 0.3512181506722207
|
| 29 |
+
TSLA_EVENT_MEAN_DEPTH = 7.365325300819055
|
| 30 |
+
TSLA_EVENT_STD_DEPTH = 8.59342838063813
|
| 31 |
+
|
| 32 |
+
# for 15 days of INTC
|
| 33 |
+
INTC_LOB_MEAN_SIZE_10 = 6222.424274871972
|
| 34 |
+
INTC_LOB_STD_SIZE_10 = 7538.341086370264
|
| 35 |
+
INTC_LOB_MEAN_PRICE_10 = 3635.766219937785
|
| 36 |
+
INTC_LOB_STD_PRICE_10 = 44.15649995373795
|
| 37 |
+
|
| 38 |
+
INTC_EVENT_MEAN_SIZE = 324.6800802006092
|
| 39 |
+
INTC_EVENT_STD_SIZE = 574.5781447696605
|
| 40 |
+
INTC_EVENT_MEAN_PRICE = 3635.78165265669
|
| 41 |
+
INTC_EVENT_STD_PRICE = 43.872407609651184
|
| 42 |
+
INTC_EVENT_MEAN_TIME = 0.025201754040915927
|
| 43 |
+
INTC_EVENT_STD_TIME = 0.11013627432323592
|
| 44 |
+
INTC_EVENT_MEAN_DEPTH = 1.3685517399834501
|
| 45 |
+
INTC_EVENT_STD_DEPTH = 2.333747222206966
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
LOBSTER_HORIZONS = [10, 20, 50, 100]
|
| 51 |
+
PRECISION = 32
|
| 52 |
+
N_LOB_LEVELS = 10
|
| 53 |
+
LEN_LEVEL = 4
|
| 54 |
+
LEN_ORDER = 6
|
| 55 |
+
LEN_SMOOTH = 10
|
| 56 |
+
|
| 57 |
+
DATE_TRADING_DAYS = ["2015-01-02", "2015-01-30"]
|
| 58 |
+
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
|
| 59 |
+
DIR_EXPERIMENTS = "data/experiments"
|
| 60 |
+
DIR_SAVED_MODEL = "data/checkpoints"
|
| 61 |
+
DATA_DIR = "data"
|
| 62 |
+
RECON_DIR = "data/reconstructions"
|
| 63 |
+
PROJECT_NAME = ""
|
| 64 |
+
SPLIT_RATES = [0.8, 0.1, 0.1]
|
data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_10_TLOB_seed_42.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bcf32a73fe974b57778d0436132f18a76c3e71f38af2fdc1068f711bc28bcd96
|
| 3 |
+
size 32098955
|
data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_1_TLOB_seed_42.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f90706b3df6cfebb855e6a2ff3b8b32ce7c1e3301067ad8ef26c36214214e8ca
|
| 3 |
+
size 32098955
|
data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_2_TLOB_seed_42.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:641014f18977c93c6502a9c21f579d20ce9edc7e3d64b63c90716b5682273c57
|
| 3 |
+
size 32098955
|
data/checkpoints/TLOB/HuggingFace/FI-2010_horizon_5_TLOB_seed_42.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4d606d22ac0f1fad2238787a30d111af7dc975d0ea23c48a11c4c797db74bf5d
|
| 3 |
+
size 32098955
|
fI-2010.png
ADDED

|
Git LFS Details
|
main.py
ADDED
|
@@ -0,0 +1,75 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
import warnings
|
| 3 |
+
warnings.filterwarnings("ignore")
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torchvision
|
| 6 |
+
import wandb
|
| 7 |
+
import torch
|
| 8 |
+
torchvision.disable_beta_transforms_warning()
|
| 9 |
+
import constants as cst
|
| 10 |
+
import hydra
|
| 11 |
+
from config.config import Config
|
| 12 |
+
from run import run_wandb, run, sweep_init
|
| 13 |
+
from preprocessing.lobster import LOBSTERDataBuilder
|
| 14 |
+
from constants import Dataset
|
| 15 |
+
from config.config import MLPLOB, TLOB
|
| 16 |
+
|
| 17 |
+
@hydra.main(config_path="config", config_name="config")
|
| 18 |
+
def hydra_app(config: Config):
|
| 19 |
+
set_reproducibility(config.experiment.seed)
|
| 20 |
+
if (cst.DEVICE == "cpu"):
|
| 21 |
+
accelerator = "cpu"
|
| 22 |
+
else:
|
| 23 |
+
accelerator = "gpu"
|
| 24 |
+
if config.experiment.dataset_type == Dataset.FI_2010:
|
| 25 |
+
config.experiment.batch_size = 32
|
| 26 |
+
if config.model.type.value == "MLPLOB" or config.model.type.value == "TLOB":
|
| 27 |
+
config.model.hyperparameters_fixed["hidden_dim"] = 144
|
| 28 |
+
else:
|
| 29 |
+
config.experiment.batch_size = 128
|
| 30 |
+
if config.model.type.value == "MLPLOB" or config.model.type.value == "TLOB":
|
| 31 |
+
config.model.hyperparameters_fixed["hidden_dim"] = 46
|
| 32 |
+
|
| 33 |
+
if config.experiment.dataset_type.value == "LOBSTER" and not config.experiment.is_data_preprocessed:
|
| 34 |
+
# prepare the datasets, this will save train.npy, val.npy and test.npy in the data directory
|
| 35 |
+
data_builder = LOBSTERDataBuilder(
|
| 36 |
+
stocks=config.experiment.training_stocks,
|
| 37 |
+
data_dir=cst.DATA_DIR,
|
| 38 |
+
date_trading_days=cst.DATE_TRADING_DAYS,
|
| 39 |
+
split_rates=cst.SPLIT_RATES,
|
| 40 |
+
sampling_type=config.experiment.sampling_type,
|
| 41 |
+
sampling_time=config.experiment.sampling_time,
|
| 42 |
+
sampling_quantity=config.experiment.sampling_quantity,
|
| 43 |
+
)
|
| 44 |
+
data_builder.prepare_save_datasets()
|
| 45 |
+
|
| 46 |
+
if config.experiment.is_wandb:
|
| 47 |
+
if config.experiment.is_sweep:
|
| 48 |
+
sweep_config = sweep_init(config)
|
| 49 |
+
sweep_id = wandb.sweep(sweep_config, project=cst.PROJECT_NAME, entity="")
|
| 50 |
+
wandb.agent(sweep_id, run_wandb(config, accelerator), count=sweep_config["run_cap"])
|
| 51 |
+
else:
|
| 52 |
+
start_wandb = run_wandb(config, accelerator)
|
| 53 |
+
start_wandb()
|
| 54 |
+
|
| 55 |
+
# training without using wandb
|
| 56 |
+
else:
|
| 57 |
+
run(config, accelerator)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def set_reproducibility(seed):
|
| 61 |
+
torch.manual_seed(seed)
|
| 62 |
+
np.random.seed(seed)
|
| 63 |
+
random.seed(seed)
|
| 64 |
+
|
| 65 |
+
def set_torch():
|
| 66 |
+
torch.set_default_dtype(torch.float32)
|
| 67 |
+
torch.backends.cuda.matmul.allow_tf32 = True
|
| 68 |
+
torch.backends.cudnn.allow_tf32 = True
|
| 69 |
+
torch.autograd.set_detect_anomaly(False)
|
| 70 |
+
torch.set_float32_matmul_precision('high')
|
| 71 |
+
|
| 72 |
+
if __name__ == "__main__":
|
| 73 |
+
set_torch()
|
| 74 |
+
hydra_app()
|
| 75 |
+
|
models/__pycache__/bin.cpython-310.pyc
ADDED
|
Binary file (1.95 kB). View file
|
|
|
models/__pycache__/bin.cpython-311.pyc
ADDED
|
Binary file (4.98 kB). View file
|
|
|
models/__pycache__/binctabl.cpython-311.pyc
ADDED
|
Binary file (8.74 kB). View file
|
|
|
models/__pycache__/deeplob.cpython-311.pyc
ADDED
|
Binary file (5.55 kB). View file
|
|
|
models/__pycache__/engine.cpython-310.pyc
ADDED
|
Binary file (9.72 kB). View file
|
|
|
models/__pycache__/engine.cpython-311.pyc
ADDED
|
Binary file (21.4 kB). View file
|
|
|
models/__pycache__/mlp.cpython-310.pyc
ADDED
|
Binary file (2.47 kB). View file
|
|
|
models/__pycache__/mlp.cpython-311.pyc
ADDED
|
Binary file (5.73 kB). View file
|
|
|
models/__pycache__/transformer.cpython-311.pyc
ADDED
|
Binary file (13.2 kB). View file
|
|
|
models/bin.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch import nn
|
| 3 |
+
import constants as cst
|
| 4 |
+
|
| 5 |
+
class BiN(nn.Module):
|
| 6 |
+
def __init__(self, d1, t1):
|
| 7 |
+
super().__init__()
|
| 8 |
+
self.t1 = t1
|
| 9 |
+
self.d1 = d1
|
| 10 |
+
|
| 11 |
+
bias1 = torch.Tensor(t1, 1)
|
| 12 |
+
self.B1 = nn.Parameter(bias1)
|
| 13 |
+
nn.init.constant_(self.B1, 0)
|
| 14 |
+
|
| 15 |
+
l1 = torch.Tensor(t1, 1)
|
| 16 |
+
self.l1 = nn.Parameter(l1)
|
| 17 |
+
nn.init.xavier_normal_(self.l1)
|
| 18 |
+
|
| 19 |
+
bias2 = torch.Tensor(d1, 1)
|
| 20 |
+
self.B2 = nn.Parameter(bias2)
|
| 21 |
+
nn.init.constant_(self.B2, 0)
|
| 22 |
+
|
| 23 |
+
l2 = torch.Tensor(d1, 1)
|
| 24 |
+
self.l2 = nn.Parameter(l2)
|
| 25 |
+
nn.init.xavier_normal_(self.l2)
|
| 26 |
+
|
| 27 |
+
y1 = torch.Tensor(1, )
|
| 28 |
+
self.y1 = nn.Parameter(y1)
|
| 29 |
+
nn.init.constant_(self.y1, 0.5)
|
| 30 |
+
|
| 31 |
+
y2 = torch.Tensor(1, )
|
| 32 |
+
self.y2 = nn.Parameter(y2)
|
| 33 |
+
nn.init.constant_(self.y2, 0.5)
|
| 34 |
+
|
| 35 |
+
def forward(self, x):
|
| 36 |
+
|
| 37 |
+
# if the two scalars are negative then we setting them to 0
|
| 38 |
+
if (self.y1[0] < 0):
|
| 39 |
+
y1 = torch.cuda.FloatTensor(1, )
|
| 40 |
+
self.y1 = nn.Parameter(y1)
|
| 41 |
+
nn.init.constant_(self.y1, 0.01)
|
| 42 |
+
|
| 43 |
+
if (self.y2[0] < 0):
|
| 44 |
+
y2 = torch.cuda.FloatTensor(1, )
|
| 45 |
+
self.y2 = nn.Parameter(y2)
|
| 46 |
+
nn.init.constant_(self.y2, 0.01)
|
| 47 |
+
|
| 48 |
+
# normalization along the temporal dimensione
|
| 49 |
+
T2 = torch.ones([self.t1, 1], device=cst.DEVICE)
|
| 50 |
+
x2 = torch.mean(x, dim=2)
|
| 51 |
+
x2 = torch.reshape(x2, (x2.shape[0], x2.shape[1], 1))
|
| 52 |
+
|
| 53 |
+
std = torch.std(x, dim=2)
|
| 54 |
+
std = torch.reshape(std, (std.shape[0], std.shape[1], 1))
|
| 55 |
+
# it can be possible that the std of some temporal slices is 0, and this produces inf values, so we have to set them to one
|
| 56 |
+
std[std < 1e-4] = 1
|
| 57 |
+
|
| 58 |
+
diff = x - (x2 @ (T2.T))
|
| 59 |
+
Z2 = diff / (std @ (T2.T))
|
| 60 |
+
|
| 61 |
+
X2 = self.l2 @ T2.T
|
| 62 |
+
X2 = X2 * Z2
|
| 63 |
+
X2 = X2 + (self.B2 @ T2.T)
|
| 64 |
+
|
| 65 |
+
# normalization along the feature dimension
|
| 66 |
+
T1 = torch.ones([self.d1, 1], device=cst.DEVICE)
|
| 67 |
+
x1 = torch.mean(x, dim=1)
|
| 68 |
+
x1 = torch.reshape(x1, (x1.shape[0], x1.shape[1], 1))
|
| 69 |
+
|
| 70 |
+
std = torch.std(x, dim=1)
|
| 71 |
+
std = torch.reshape(std, (std.shape[0], std.shape[1], 1))
|
| 72 |
+
|
| 73 |
+
op1 = x1 @ T1.T
|
| 74 |
+
op1 = torch.permute(op1, (0, 2, 1))
|
| 75 |
+
|
| 76 |
+
op2 = std @ T1.T
|
| 77 |
+
op2 = torch.permute(op2, (0, 2, 1))
|
| 78 |
+
|
| 79 |
+
z1 = (x - op1) / (op2)
|
| 80 |
+
X1 = (T1 @ self.l1.T)
|
| 81 |
+
X1 = X1 * z1
|
| 82 |
+
X1 = X1 + (T1 @ self.B1.T)
|
| 83 |
+
|
| 84 |
+
# weighing the imporance of temporal and feature normalization
|
| 85 |
+
x = self.y1 * X1 + self.y2 * X2
|
| 86 |
+
|
| 87 |
+
return x
|
models/binctabl.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
from models.bin import BiN
|
| 3 |
+
import torch
|
| 4 |
+
import constants as cst
|
| 5 |
+
|
| 6 |
+
class TABL_layer(nn.Module):
|
| 7 |
+
def __init__(self, d2, d1, t1, t2):
|
| 8 |
+
super().__init__()
|
| 9 |
+
self.t1 = t1
|
| 10 |
+
|
| 11 |
+
weight = torch.Tensor(d2, d1)
|
| 12 |
+
self.W1 = nn.Parameter(weight)
|
| 13 |
+
nn.init.kaiming_uniform_(self.W1, nonlinearity='relu')
|
| 14 |
+
|
| 15 |
+
weight2 = torch.Tensor(t1, t1)
|
| 16 |
+
self.W = nn.Parameter(weight2)
|
| 17 |
+
nn.init.constant_(self.W, 1/t1)
|
| 18 |
+
|
| 19 |
+
weight3 = torch.Tensor(t1, t2)
|
| 20 |
+
self.W2 = nn.Parameter(weight3)
|
| 21 |
+
nn.init.kaiming_uniform_(self.W2, nonlinearity='relu')
|
| 22 |
+
|
| 23 |
+
bias1 = torch.Tensor(d2, t2)
|
| 24 |
+
self.B = nn.Parameter(bias1)
|
| 25 |
+
nn.init.constant_(self.B, 0)
|
| 26 |
+
|
| 27 |
+
l = torch.Tensor(1,)
|
| 28 |
+
self.l = nn.Parameter(l)
|
| 29 |
+
nn.init.constant_(self.l, 0.5)
|
| 30 |
+
|
| 31 |
+
self.activation = nn.ReLU()
|
| 32 |
+
|
| 33 |
+
def forward(self, X):
|
| 34 |
+
|
| 35 |
+
#maintaining the weight parameter between 0 and 1.
|
| 36 |
+
if (self.l[0] < 0):
|
| 37 |
+
l = torch.Tensor(1,).to(cst.DEVICE)
|
| 38 |
+
self.l = nn.Parameter(l)
|
| 39 |
+
nn.init.constant_(self.l, 0.0)
|
| 40 |
+
|
| 41 |
+
if (self.l[0] > 1):
|
| 42 |
+
l = torch.Tensor(1,).to(cst.DEVICE)
|
| 43 |
+
self.l = nn.Parameter(l)
|
| 44 |
+
nn.init.constant_(self.l, 1.0)
|
| 45 |
+
|
| 46 |
+
#modelling the dependence along the first mode of X while keeping the temporal order intact (7)
|
| 47 |
+
X = self.W1 @ X
|
| 48 |
+
|
| 49 |
+
#enforcing constant (1) on the diagonal
|
| 50 |
+
W = self.W -self.W *torch.eye(self.t1,dtype=torch.float32).to(cst.DEVICE)+torch.eye(self.t1,dtype=torch.float32).to(cst.DEVICE)/self.t1
|
| 51 |
+
|
| 52 |
+
#attention, the aim of the second step is to learn how important the temporal instances are to each other (8)
|
| 53 |
+
E = X @ W
|
| 54 |
+
|
| 55 |
+
#computing the attention mask (9)
|
| 56 |
+
A = torch.softmax(E, dim=-1)
|
| 57 |
+
|
| 58 |
+
#applying a soft attention mechanism (10)
|
| 59 |
+
#he attention mask A obtained from the third step is used to zero out the effect of unimportant elements
|
| 60 |
+
X = self.l[0] * (X) + (1.0 - self.l[0])*X*A
|
| 61 |
+
|
| 62 |
+
#the final step of the proposed layer estimates the temporal mapping W2, after the bias shift (11)
|
| 63 |
+
y = X @ self.W2 + self.B
|
| 64 |
+
return y
|
| 65 |
+
|
| 66 |
+
class BL_layer(nn.Module):
|
| 67 |
+
def __init__(self, d2, d1, t1, t2):
|
| 68 |
+
super().__init__()
|
| 69 |
+
weight1 = torch.Tensor(d2, d1)
|
| 70 |
+
self.W1 = nn.Parameter(weight1)
|
| 71 |
+
nn.init.kaiming_uniform_(self.W1, nonlinearity='relu')
|
| 72 |
+
|
| 73 |
+
weight2 = torch.Tensor(t1, t2)
|
| 74 |
+
self.W2 = nn.Parameter(weight2)
|
| 75 |
+
nn.init.kaiming_uniform_(self.W2, nonlinearity='relu')
|
| 76 |
+
|
| 77 |
+
bias1 = torch.zeros((d2, t2))
|
| 78 |
+
self.B = nn.Parameter(bias1)
|
| 79 |
+
nn.init.constant_(self.B, 0)
|
| 80 |
+
|
| 81 |
+
self.activation = nn.ReLU()
|
| 82 |
+
|
| 83 |
+
def forward(self, x):
|
| 84 |
+
|
| 85 |
+
x = self.activation(self.W1 @ x @ self.W2 + self.B)
|
| 86 |
+
|
| 87 |
+
return x
|
| 88 |
+
|
| 89 |
+
class BiN_CTABL(nn.Module):
|
| 90 |
+
def __init__(self, d2, d1, t1, t2, d3, t3, d4, t4):
|
| 91 |
+
super().__init__()
|
| 92 |
+
|
| 93 |
+
self.BiN = BiN(d1, t1)
|
| 94 |
+
self.BL = BL_layer(d2, d1, t1, t2)
|
| 95 |
+
self.BL2 = BL_layer(d3, d2, t2, t3)
|
| 96 |
+
self.TABL = TABL_layer(d4, d3, t3, t4)
|
| 97 |
+
self.dropout = nn.Dropout(0.1)
|
| 98 |
+
|
| 99 |
+
def forward(self, x):
|
| 100 |
+
x = x.permute(0, 2, 1)
|
| 101 |
+
#first of all we pass the input to the BiN layer, then we use the C(TABL) architecture
|
| 102 |
+
x = self.BiN(x)
|
| 103 |
+
|
| 104 |
+
self.max_norm_(self.BL.W1.data)
|
| 105 |
+
self.max_norm_(self.BL.W2.data)
|
| 106 |
+
x = self.BL(x)
|
| 107 |
+
x = self.dropout(x)
|
| 108 |
+
|
| 109 |
+
self.max_norm_(self.BL2.W1.data)
|
| 110 |
+
self.max_norm_(self.BL2.W2.data)
|
| 111 |
+
x = self.BL2(x)
|
| 112 |
+
x = self.dropout(x)
|
| 113 |
+
|
| 114 |
+
self.max_norm_(self.TABL.W1.data)
|
| 115 |
+
self.max_norm_(self.TABL.W.data)
|
| 116 |
+
self.max_norm_(self.TABL.W2.data)
|
| 117 |
+
x = self.TABL(x)
|
| 118 |
+
x = torch.squeeze(x)
|
| 119 |
+
x = torch.softmax(x, 1)
|
| 120 |
+
|
| 121 |
+
return x
|
| 122 |
+
|
| 123 |
+
def max_norm_(self, w):
|
| 124 |
+
with torch.no_grad():
|
| 125 |
+
if (torch.linalg.matrix_norm(w) > 10.0):
|
| 126 |
+
norm = torch.linalg.matrix_norm(w)
|
| 127 |
+
desired = torch.clamp(norm, min=0.0, max=10.0)
|
| 128 |
+
w *= (desired / (1e-8 + norm))
|
| 129 |
+
|
models/deeplob.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class DeepLOB(nn.Module):
|
| 6 |
+
def __init__(self):
|
| 7 |
+
super().__init__()
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# convolution blocks
|
| 11 |
+
self.conv1 = nn.Sequential(
|
| 12 |
+
nn.Conv2d(in_channels=1, out_channels=32, kernel_size=(1, 2), stride=(1, 2)),
|
| 13 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 14 |
+
# nn.Tanh(),
|
| 15 |
+
nn.BatchNorm2d(32),
|
| 16 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
|
| 17 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 18 |
+
nn.BatchNorm2d(32),
|
| 19 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
|
| 20 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 21 |
+
nn.BatchNorm2d(32),
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
self.conv2 = nn.Sequential(
|
| 25 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(1, 2), stride=(1, 2)),
|
| 26 |
+
nn.Tanh(),
|
| 27 |
+
nn.BatchNorm2d(32),
|
| 28 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
|
| 29 |
+
nn.Tanh(),
|
| 30 |
+
nn.BatchNorm2d(32),
|
| 31 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
|
| 32 |
+
nn.Tanh(),
|
| 33 |
+
nn.BatchNorm2d(32),
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
self.conv3 = nn.Sequential(
|
| 37 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(1, 10)),
|
| 38 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 39 |
+
nn.BatchNorm2d(32),
|
| 40 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
|
| 41 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 42 |
+
nn.BatchNorm2d(32),
|
| 43 |
+
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(4, 1)),
|
| 44 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 45 |
+
nn.BatchNorm2d(32),
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
# inception modules
|
| 49 |
+
self.inp1 = nn.Sequential(
|
| 50 |
+
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
|
| 51 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 52 |
+
nn.BatchNorm2d(64),
|
| 53 |
+
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(3, 1), padding='same'),
|
| 54 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 55 |
+
nn.BatchNorm2d(64),
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
self.inp2 = nn.Sequential(
|
| 59 |
+
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
|
| 60 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 61 |
+
nn.BatchNorm2d(64),
|
| 62 |
+
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=(5, 1), padding='same'),
|
| 63 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 64 |
+
nn.BatchNorm2d(64),
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
self.inp3 = nn.Sequential(
|
| 68 |
+
nn.MaxPool2d((3, 1), stride=(1, 1), padding=(1, 0)),
|
| 69 |
+
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(1, 1), padding='same'),
|
| 70 |
+
nn.LeakyReLU(negative_slope=0.01),
|
| 71 |
+
nn.BatchNorm2d(64),
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
# lstm layers
|
| 75 |
+
self.lstm = nn.LSTM(input_size=192, hidden_size=64, num_layers=1, batch_first=True)
|
| 76 |
+
self.fc1 = nn.Linear(64, 3)
|
| 77 |
+
|
| 78 |
+
self.softmax = nn.Softmax(dim=1)
|
| 79 |
+
|
| 80 |
+
def forward(self, x):
|
| 81 |
+
x = x[:, None, :, :] # none stands for the channel
|
| 82 |
+
|
| 83 |
+
x = self.conv1(x)
|
| 84 |
+
x = self.conv2(x)
|
| 85 |
+
x = self.conv3(x)
|
| 86 |
+
|
| 87 |
+
x_inp1 = self.inp1(x)
|
| 88 |
+
x_inp2 = self.inp2(x)
|
| 89 |
+
x_inp3 = self.inp3(x)
|
| 90 |
+
|
| 91 |
+
x = torch.cat((x_inp1, x_inp2, x_inp3), dim=1)
|
| 92 |
+
|
| 93 |
+
# x = torch.transpose(x, 1, 2)
|
| 94 |
+
x = x.permute(0, 2, 1, 3)
|
| 95 |
+
x = torch.reshape(x, (-1, x.shape[1], x.shape[2]))
|
| 96 |
+
|
| 97 |
+
out, _ = self.lstm(x)
|
| 98 |
+
|
| 99 |
+
out = out[:, -1, :]
|
| 100 |
+
out = self.fc1(out)
|
| 101 |
+
out = self.softmax(out)
|
| 102 |
+
return out
|
models/engine.py
ADDED
|
@@ -0,0 +1,294 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
from lightning import LightningModule
|
| 3 |
+
import numpy as np
|
| 4 |
+
from sklearn.metrics import classification_report, precision_recall_curve
|
| 5 |
+
from torch import nn
|
| 6 |
+
import os
|
| 7 |
+
import torch
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
import wandb
|
| 10 |
+
import seaborn as sns
|
| 11 |
+
from lion_pytorch import Lion
|
| 12 |
+
from torch_ema import ExponentialMovingAverage
|
| 13 |
+
from utils.utils_model import pick_model
|
| 14 |
+
import constants as cst
|
| 15 |
+
from scipy.stats import mode
|
| 16 |
+
|
| 17 |
+
from visualizations.attentions import plot_mean_att_distance
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class Engine(LightningModule):
|
| 21 |
+
def __init__(
|
| 22 |
+
self,
|
| 23 |
+
seq_size,
|
| 24 |
+
horizon,
|
| 25 |
+
max_epochs,
|
| 26 |
+
model_type,
|
| 27 |
+
is_wandb,
|
| 28 |
+
experiment_type,
|
| 29 |
+
lr,
|
| 30 |
+
optimizer,
|
| 31 |
+
filename_ckpt,
|
| 32 |
+
num_features,
|
| 33 |
+
dataset_type,
|
| 34 |
+
num_layers=4,
|
| 35 |
+
hidden_dim=256,
|
| 36 |
+
num_heads=8,
|
| 37 |
+
is_sin_emb=True,
|
| 38 |
+
len_test_dataloader=None,
|
| 39 |
+
plot_att=False
|
| 40 |
+
):
|
| 41 |
+
super().__init__()
|
| 42 |
+
self.seq_size = seq_size
|
| 43 |
+
self.dataset_type = dataset_type
|
| 44 |
+
self.horizon = horizon
|
| 45 |
+
self.max_epochs = max_epochs
|
| 46 |
+
self.model_type = model_type
|
| 47 |
+
self.num_heads = num_heads
|
| 48 |
+
self.is_wandb = is_wandb
|
| 49 |
+
self.len_test_dataloader = len_test_dataloader
|
| 50 |
+
self.lr = lr
|
| 51 |
+
self.optimizer = optimizer
|
| 52 |
+
self.filename_ckpt = filename_ckpt
|
| 53 |
+
self.hidden_dim = hidden_dim
|
| 54 |
+
self.num_layers = num_layers
|
| 55 |
+
self.num_features = num_features
|
| 56 |
+
self.experiment_type = experiment_type
|
| 57 |
+
self.model = pick_model(model_type, hidden_dim, num_layers, seq_size, num_features, num_heads, is_sin_emb, dataset_type)
|
| 58 |
+
self.ema = ExponentialMovingAverage(self.parameters(), decay=0.999)
|
| 59 |
+
self.ema.to(cst.DEVICE)
|
| 60 |
+
self.loss_function = nn.CrossEntropyLoss()
|
| 61 |
+
self.train_losses = []
|
| 62 |
+
self.val_losses = []
|
| 63 |
+
self.test_losses = []
|
| 64 |
+
self.test_targets = []
|
| 65 |
+
self.test_predictions = []
|
| 66 |
+
self.test_proba = []
|
| 67 |
+
self.val_targets = []
|
| 68 |
+
self.val_loss = np.inf
|
| 69 |
+
self.val_predictions = []
|
| 70 |
+
self.min_loss = np.inf
|
| 71 |
+
self.save_hyperparameters()
|
| 72 |
+
self.last_path_ckpt = None
|
| 73 |
+
self.first_test = True
|
| 74 |
+
self.plot_att = plot_att
|
| 75 |
+
|
| 76 |
+
def forward(self, x, plot_this_att=False, batch_idx=None):
|
| 77 |
+
if self.model_type == "TLOB":
|
| 78 |
+
output, att_temporal, att_feature = self.model(x, plot_this_att)
|
| 79 |
+
else:
|
| 80 |
+
output = self.model(x)
|
| 81 |
+
if self.is_wandb and plot_this_att and self.model_type == "TLOB":
|
| 82 |
+
for l in range(len(att_temporal)):
|
| 83 |
+
for i in range(self.num_heads):
|
| 84 |
+
plt.figure(figsize=(10, 8))
|
| 85 |
+
sns.heatmap(att_temporal[l, i], fmt=".2f", cmap="viridis")
|
| 86 |
+
plt.title(f'Temporal Attention Layer {l} Head {i}')
|
| 87 |
+
wandb.log({f"Temporal Attention Layer {l} Head {i} for batch {batch_idx}": wandb.Image(plt)})
|
| 88 |
+
plt.close()
|
| 89 |
+
for l in range(len(att_feature)):
|
| 90 |
+
for i in range(self.num_heads):
|
| 91 |
+
plt.figure(figsize=(10, 8))
|
| 92 |
+
sns.heatmap(att_feature[l, i], fmt=".2f", cmap="viridis")
|
| 93 |
+
plt.title(f'Feature Attention Layer {l} Head {i}')
|
| 94 |
+
wandb.log({f"Feature Attention Layer {l} Head {i} for batch {batch_idx}": wandb.Image(plt)})
|
| 95 |
+
plt.close()
|
| 96 |
+
return output
|
| 97 |
+
|
| 98 |
+
def loss(self, y_hat, y):
|
| 99 |
+
return self.loss_function(y_hat, y)
|
| 100 |
+
|
| 101 |
+
def training_step(self, batch, batch_idx):
|
| 102 |
+
x, y = batch
|
| 103 |
+
y_hat = self.forward(x)
|
| 104 |
+
batch_loss = self.loss(y_hat, y)
|
| 105 |
+
batch_loss_mean = torch.mean(batch_loss)
|
| 106 |
+
self.train_losses.append(batch_loss_mean.item())
|
| 107 |
+
self.ema.update()
|
| 108 |
+
if batch_idx % 1000 == 0:
|
| 109 |
+
print(f'train loss: {sum(self.train_losses) / len(self.train_losses)}')
|
| 110 |
+
return batch_loss_mean
|
| 111 |
+
|
| 112 |
+
def on_train_epoch_start(self) -> None:
|
| 113 |
+
print(f'learning rate: {self.optimizer.param_groups[0]["lr"]}')
|
| 114 |
+
|
| 115 |
+
def validation_step(self, batch, batch_idx):
|
| 116 |
+
x, y = batch
|
| 117 |
+
# Validation: with EMA
|
| 118 |
+
with self.ema.average_parameters():
|
| 119 |
+
y_hat = self.forward(x)
|
| 120 |
+
batch_loss = self.loss(y_hat, y)
|
| 121 |
+
self.val_targets.append(y.cpu().numpy())
|
| 122 |
+
self.val_predictions.append(y_hat.argmax(dim=1).cpu().numpy())
|
| 123 |
+
batch_loss_mean = torch.mean(batch_loss)
|
| 124 |
+
self.val_losses.append(batch_loss_mean.item())
|
| 125 |
+
return batch_loss_mean
|
| 126 |
+
|
| 127 |
+
def on_test_epoch_start(self):
|
| 128 |
+
# Extract 30 random numbers from the length of the test_dataloader
|
| 129 |
+
random_indices = random.sample(range(self.len_test_dataloader), 5)
|
| 130 |
+
print(f'Random indices: {random_indices}')
|
| 131 |
+
self.random_indices = random_indices # Store the random indices if needed
|
| 132 |
+
return
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
def test_step(self, batch, batch_idx):
|
| 136 |
+
x, y = batch
|
| 137 |
+
# Test: with EMA
|
| 138 |
+
if batch_idx in self.random_indices and self.model_type == "TLOB" and self.first_test and self.plot_att:
|
| 139 |
+
plot_this_att = True
|
| 140 |
+
print(f'Plotting attention for batch {batch_idx}')
|
| 141 |
+
else:
|
| 142 |
+
plot_this_att = False
|
| 143 |
+
if self.experiment_type == "TRAINING":
|
| 144 |
+
with self.ema.average_parameters():
|
| 145 |
+
y_hat = self.forward(x, plot_this_att, batch_idx)
|
| 146 |
+
batch_loss = self.loss(y_hat, y)
|
| 147 |
+
self.test_targets.append(y.cpu().numpy())
|
| 148 |
+
self.test_predictions.append(y_hat.argmax(dim=1).cpu().numpy())
|
| 149 |
+
self.test_proba.append(torch.softmax(y_hat, dim=1)[:, 1].cpu().numpy())
|
| 150 |
+
batch_loss_mean = torch.mean(batch_loss)
|
| 151 |
+
self.test_losses.append(batch_loss_mean.item())
|
| 152 |
+
else:
|
| 153 |
+
y_hat = self.forward(x, plot_this_att, batch_idx)
|
| 154 |
+
batch_loss = self.loss(y_hat, y)
|
| 155 |
+
self.test_targets.append(y.cpu().numpy())
|
| 156 |
+
self.test_predictions.append(y_hat.argmax(dim=1).cpu().numpy())
|
| 157 |
+
self.test_proba.append(torch.softmax(y_hat, dim=1)[:, 1].cpu().numpy())
|
| 158 |
+
batch_loss_mean = torch.mean(batch_loss)
|
| 159 |
+
self.test_losses.append(batch_loss_mean.item())
|
| 160 |
+
return batch_loss_mean
|
| 161 |
+
|
| 162 |
+
def on_validation_epoch_start(self) -> None:
|
| 163 |
+
loss = sum(self.train_losses) / len(self.train_losses)
|
| 164 |
+
self.train_losses = []
|
| 165 |
+
if self.is_wandb:
|
| 166 |
+
wandb.log({"train_loss": loss})
|
| 167 |
+
print(f'Train loss on epoch {self.current_epoch}: {loss}')
|
| 168 |
+
|
| 169 |
+
def on_validation_epoch_end(self) -> None:
|
| 170 |
+
self.val_loss = sum(self.val_losses) / len(self.val_losses)
|
| 171 |
+
self.val_losses = []
|
| 172 |
+
|
| 173 |
+
# model checkpointing
|
| 174 |
+
if self.val_loss < self.min_loss:
|
| 175 |
+
# if the improvement is less than 0.0005, we halve the learning rate
|
| 176 |
+
if self.val_loss - self.min_loss > -0.001:
|
| 177 |
+
self.optimizer.param_groups[0]["lr"] /= 2
|
| 178 |
+
self.min_loss = self.val_loss
|
| 179 |
+
self.model_checkpointing(self.val_loss)
|
| 180 |
+
else:
|
| 181 |
+
self.optimizer.param_groups[0]["lr"] /= 2
|
| 182 |
+
|
| 183 |
+
self.log("val_loss", self.val_loss)
|
| 184 |
+
print(f'Validation loss on epoch {self.current_epoch}: {self.val_loss}')
|
| 185 |
+
targets = np.concatenate(self.val_targets)
|
| 186 |
+
predictions = np.concatenate(self.val_predictions)
|
| 187 |
+
class_report = classification_report(targets, predictions, digits=4, output_dict=True)
|
| 188 |
+
print(classification_report(targets, predictions, digits=4))
|
| 189 |
+
self.log("val_f1_score", class_report["macro avg"]["f1-score"])
|
| 190 |
+
self.log("val_accuracy", class_report["accuracy"])
|
| 191 |
+
self.log("val_precision", class_report["macro avg"]["precision"])
|
| 192 |
+
self.log("val_recall", class_report["macro avg"]["recall"])
|
| 193 |
+
self.val_targets = []
|
| 194 |
+
self.val_predictions = []
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def on_test_epoch_end(self) -> None:
|
| 198 |
+
targets = np.concatenate(self.test_targets)
|
| 199 |
+
predictions = np.concatenate(self.test_predictions)
|
| 200 |
+
class_report = classification_report(targets, predictions, digits=4, output_dict=True)
|
| 201 |
+
print(classification_report(targets, predictions, digits=4))
|
| 202 |
+
self.log("test_loss", sum(self.test_losses) / len(self.test_losses))
|
| 203 |
+
self.log("f1_score", class_report["macro avg"]["f1-score"])
|
| 204 |
+
self.log("accuracy", class_report["accuracy"])
|
| 205 |
+
self.log("precision", class_report["macro avg"]["precision"])
|
| 206 |
+
self.log("recall", class_report["macro avg"]["recall"])
|
| 207 |
+
filename_ckpt = ("val_loss=" + str(round(self.val_loss, 3)) +
|
| 208 |
+
"_epoch=" + str(self.current_epoch) +
|
| 209 |
+
"_" + self.filename_ckpt +
|
| 210 |
+
"last.ckpt"
|
| 211 |
+
)
|
| 212 |
+
path_ckpt = cst.DIR_SAVED_MODEL + "/" + str(self.model_type) + "/" + filename_ckpt
|
| 213 |
+
self.test_targets = []
|
| 214 |
+
self.test_predictions = []
|
| 215 |
+
self.test_losses = []
|
| 216 |
+
self.first_test = False
|
| 217 |
+
test_proba = np.concatenate(self.test_proba)
|
| 218 |
+
precision, recall, _ = precision_recall_curve(targets, test_proba, pos_label=1)
|
| 219 |
+
self.plot_pr_curves(recall, precision, self.is_wandb)
|
| 220 |
+
with self.ema.average_parameters():
|
| 221 |
+
self.trainer.save_checkpoint(path_ckpt)
|
| 222 |
+
if self.model_type == "TLOB" and self.plot_att:
|
| 223 |
+
plot = plot_mean_att_distance(np.array(self.model.mean_att_distance_temporal).mean(axis=0))
|
| 224 |
+
if self.is_wandb:
|
| 225 |
+
wandb.log({"mean_att_distance": wandb.Image(plot)})
|
| 226 |
+
|
| 227 |
+
def configure_optimizers(self):
|
| 228 |
+
if self.model_type == "DEEPLOB":
|
| 229 |
+
eps = 1
|
| 230 |
+
else:
|
| 231 |
+
eps = 1e-8
|
| 232 |
+
if self.optimizer == 'Adam':
|
| 233 |
+
self.optimizer = torch.optim.Adam(self.parameters(), lr=self.lr, eps=eps)
|
| 234 |
+
elif self.optimizer == 'SGD':
|
| 235 |
+
self.optimizer = torch.optim.SGD(self.parameters(), lr=self.lr, momentum=0.9)
|
| 236 |
+
elif self.optimizer == 'Lion':
|
| 237 |
+
self.optimizer = Lion(self.parameters(), lr=self.lr)
|
| 238 |
+
return self.optimizer
|
| 239 |
+
|
| 240 |
+
def _define_log_metrics(self):
|
| 241 |
+
wandb.define_metric("val_loss", summary="min")
|
| 242 |
+
|
| 243 |
+
def model_checkpointing(self, loss):
|
| 244 |
+
if self.last_path_ckpt is not None:
|
| 245 |
+
os.remove(self.last_path_ckpt)
|
| 246 |
+
filename_ckpt = ("val_loss=" + str(round(loss, 3)) +
|
| 247 |
+
"_epoch=" + str(self.current_epoch) +
|
| 248 |
+
"_" + self.filename_ckpt +
|
| 249 |
+
".ckpt"
|
| 250 |
+
)
|
| 251 |
+
path_ckpt = cst.DIR_SAVED_MODEL + "/" + str(self.model_type) + "/" + filename_ckpt
|
| 252 |
+
with self.ema.average_parameters():
|
| 253 |
+
self.trainer.save_checkpoint(path_ckpt)
|
| 254 |
+
self.last_path_ckpt = path_ckpt
|
| 255 |
+
|
| 256 |
+
def plot_pr_curves(self, recall, precision, is_wandb):
|
| 257 |
+
plt.figure(figsize=(20, 10), dpi=80)
|
| 258 |
+
plt.plot(recall, precision, label='Precision-Recall', color='black')
|
| 259 |
+
plt.xlabel('Recall')
|
| 260 |
+
plt.ylabel('Precision')
|
| 261 |
+
plt.title('Precision-Recall Curve')
|
| 262 |
+
if is_wandb:
|
| 263 |
+
wandb.log({f"precision_recall_curve_{self.dataset_type}": wandb.Image(plt)})
|
| 264 |
+
plt.savefig(cst.DIR_SAVED_MODEL + "/" + str(self.model_type) + "/" +f"precision_recall_curve_{self.dataset_type}.svg")
|
| 265 |
+
#plt.show()
|
| 266 |
+
plt.close()
|
| 267 |
+
|
| 268 |
+
def compute_most_attended(att_feature):
|
| 269 |
+
''' att_feature: list of tensors of shape (num_samples, num_layers, 2, num_heads, num_features) '''
|
| 270 |
+
att_feature = np.stack(att_feature)
|
| 271 |
+
att_feature = att_feature.transpose(1, 3, 0, 2, 4) # Use transpose instead of permute
|
| 272 |
+
''' att_feature: shape (num_layers, num_heads, num_samples, 2, num_features) '''
|
| 273 |
+
indices = att_feature[:, :, :, 1]
|
| 274 |
+
values = att_feature[:, :, :, 0]
|
| 275 |
+
most_frequent_indices = np.zeros((indices.shape[0], indices.shape[1], indices.shape[3]), dtype=int)
|
| 276 |
+
average_values = np.zeros((indices.shape[0], indices.shape[1], indices.shape[3]))
|
| 277 |
+
for layer in range(indices.shape[0]):
|
| 278 |
+
for head in range(indices.shape[1]):
|
| 279 |
+
for seq in range(indices.shape[3]):
|
| 280 |
+
# Extract the indices for the current layer and sequence element
|
| 281 |
+
current_indices = indices[layer, head, :, seq]
|
| 282 |
+
current_values = values[layer, head, :, seq]
|
| 283 |
+
# Find the most frequent index
|
| 284 |
+
most_frequent_index = mode(current_indices, keepdims=False)[0]
|
| 285 |
+
# Store the result
|
| 286 |
+
most_frequent_indices[layer, head, seq] = most_frequent_index
|
| 287 |
+
# Compute the average value for the most frequent index
|
| 288 |
+
avg_value = np.mean(current_values[current_indices == most_frequent_index])
|
| 289 |
+
# Store the average value
|
| 290 |
+
average_values[layer, head, seq] = avg_value
|
| 291 |
+
return most_frequent_indices, average_values
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
|
models/mlplob.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
import torch
|
| 3 |
+
from models.bin import BiN
|
| 4 |
+
|
| 5 |
+
class MLPLOB(nn.Module):
|
| 6 |
+
def __init__(self,
|
| 7 |
+
hidden_dim: int,
|
| 8 |
+
num_layers: int,
|
| 9 |
+
seq_size: int,
|
| 10 |
+
num_features: int,
|
| 11 |
+
dataset_type: str
|
| 12 |
+
) -> None:
|
| 13 |
+
super().__init__()
|
| 14 |
+
|
| 15 |
+
self.hidden_dim = hidden_dim
|
| 16 |
+
self.num_layers = num_layers
|
| 17 |
+
self.dataset_type = dataset_type
|
| 18 |
+
self.layers = nn.ModuleList()
|
| 19 |
+
self.order_type_embedder = nn.Embedding(3, 1)
|
| 20 |
+
self.first_layer = nn.Linear(num_features, hidden_dim)
|
| 21 |
+
self.norm_layer = BiN(num_features, seq_size)
|
| 22 |
+
self.layers.append(self.first_layer)
|
| 23 |
+
self.layers.append(nn.GELU())
|
| 24 |
+
for i in range(num_layers):
|
| 25 |
+
if i != num_layers-1:
|
| 26 |
+
self.layers.append(MLP(hidden_dim, hidden_dim*4, hidden_dim))
|
| 27 |
+
self.layers.append(MLP(seq_size, seq_size*4, seq_size))
|
| 28 |
+
else:
|
| 29 |
+
self.layers.append(MLP(hidden_dim, hidden_dim*2, hidden_dim//4))
|
| 30 |
+
self.layers.append(MLP(seq_size, seq_size*2, seq_size//4))
|
| 31 |
+
|
| 32 |
+
total_dim = (hidden_dim//4)*(seq_size//4)
|
| 33 |
+
self.final_layers = nn.ModuleList()
|
| 34 |
+
while total_dim > 128:
|
| 35 |
+
self.final_layers.append(nn.Linear(total_dim, total_dim//4))
|
| 36 |
+
self.final_layers.append(nn.GELU())
|
| 37 |
+
total_dim = total_dim//4
|
| 38 |
+
self.final_layers.append(nn.Linear(total_dim, 3))
|
| 39 |
+
|
| 40 |
+
def forward(self, input):
|
| 41 |
+
if self.dataset_type == "LOBSTER":
|
| 42 |
+
continuous_features = torch.cat([input[:, :, :41], input[:, :, 42:]], dim=2)
|
| 43 |
+
order_type = input[:, :, 41].long()
|
| 44 |
+
order_type_emb = self.order_type_embedder(order_type).detach()
|
| 45 |
+
x = torch.cat([continuous_features, order_type_emb], dim=2)
|
| 46 |
+
else:
|
| 47 |
+
x = input
|
| 48 |
+
x = x.permute(0, 2, 1)
|
| 49 |
+
x = self.norm_layer(x)
|
| 50 |
+
x = x.permute(0, 2, 1)
|
| 51 |
+
for layer in self.layers:
|
| 52 |
+
x = layer(x)
|
| 53 |
+
x = x.permute(0, 2, 1)
|
| 54 |
+
x = x.reshape(x.shape[0], -1)
|
| 55 |
+
for layer in self.final_layers:
|
| 56 |
+
x = layer(x)
|
| 57 |
+
return x
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class MLP(nn.Module):
|
| 61 |
+
def __init__(self,
|
| 62 |
+
start_dim: int,
|
| 63 |
+
hidden_dim: int,
|
| 64 |
+
final_dim: int
|
| 65 |
+
) -> None:
|
| 66 |
+
super().__init__()
|
| 67 |
+
|
| 68 |
+
self.layer_norm = nn.LayerNorm(final_dim)
|
| 69 |
+
self.fc = nn.Linear(start_dim, hidden_dim)
|
| 70 |
+
self.fc2 = nn.Linear(hidden_dim, final_dim)
|
| 71 |
+
self.gelu = nn.GELU()
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
residual = x
|
| 75 |
+
x = self.fc(x)
|
| 76 |
+
x = self.gelu(x)
|
| 77 |
+
x = self.fc2(x)
|
| 78 |
+
if x.shape[2] == residual.shape[2]:
|
| 79 |
+
x = x + residual
|
| 80 |
+
x = self.layer_norm(x)
|
| 81 |
+
x = self.gelu(x)
|
| 82 |
+
return x
|
| 83 |
+
|
models/tlob.py
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch import nn
|
| 2 |
+
import torch
|
| 3 |
+
from einops import rearrange
|
| 4 |
+
import constants as cst
|
| 5 |
+
from models.bin import BiN
|
| 6 |
+
from models.mlplob import MLP
|
| 7 |
+
import numpy as np
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
import seaborn as sns
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class ComputeQKV(nn.Module):
|
| 13 |
+
def __init__(self, hidden_dim: int, num_heads: int):
|
| 14 |
+
super().__init__()
|
| 15 |
+
self.hidden_dim = hidden_dim
|
| 16 |
+
self.num_heads = num_heads
|
| 17 |
+
self.q = nn.Linear(hidden_dim, hidden_dim*num_heads)
|
| 18 |
+
self.k = nn.Linear(hidden_dim, hidden_dim*num_heads)
|
| 19 |
+
self.v = nn.Linear(hidden_dim, hidden_dim*num_heads)
|
| 20 |
+
|
| 21 |
+
def forward(self, x):
|
| 22 |
+
q = self.q(x)
|
| 23 |
+
k = self.k(x)
|
| 24 |
+
v = self.v(x)
|
| 25 |
+
return q, k, v
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class TransformerLayer(nn.Module):
|
| 29 |
+
def __init__(self, hidden_dim: int, num_heads: int, final_dim: int):
|
| 30 |
+
super().__init__()
|
| 31 |
+
self.hidden_dim = hidden_dim
|
| 32 |
+
self.num_heads = num_heads
|
| 33 |
+
self.norm = nn.LayerNorm(hidden_dim)
|
| 34 |
+
self.qkv = ComputeQKV(hidden_dim, num_heads)
|
| 35 |
+
self.attention = nn.MultiheadAttention(hidden_dim*num_heads, num_heads, batch_first=True, device=cst.DEVICE)
|
| 36 |
+
self.mlp = MLP(hidden_dim, hidden_dim*4, final_dim)
|
| 37 |
+
self.w0 = nn.Linear(hidden_dim*num_heads, hidden_dim)
|
| 38 |
+
|
| 39 |
+
def forward(self, x):
|
| 40 |
+
res = x
|
| 41 |
+
q, k, v = self.qkv(x)
|
| 42 |
+
x, att = self.attention(q, k, v, average_attn_weights=False, need_weights=True)
|
| 43 |
+
x = self.w0(x)
|
| 44 |
+
x = x + res
|
| 45 |
+
x = self.norm(x)
|
| 46 |
+
x = self.mlp(x)
|
| 47 |
+
if x.shape[-1] == res.shape[-1]:
|
| 48 |
+
x = x + res
|
| 49 |
+
return x, att
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class TLOB(nn.Module):
|
| 53 |
+
def __init__(self,
|
| 54 |
+
hidden_dim: int,
|
| 55 |
+
num_layers: int,
|
| 56 |
+
seq_size: int,
|
| 57 |
+
num_features: int,
|
| 58 |
+
num_heads: int,
|
| 59 |
+
is_sin_emb: bool,
|
| 60 |
+
dataset_type: str
|
| 61 |
+
) -> None:
|
| 62 |
+
super().__init__()
|
| 63 |
+
|
| 64 |
+
self.hidden_dim = hidden_dim
|
| 65 |
+
self.num_layers = num_layers
|
| 66 |
+
self.is_sin_emb = is_sin_emb
|
| 67 |
+
self.seq_size = seq_size
|
| 68 |
+
self.num_heads = num_heads
|
| 69 |
+
self.dataset_type = dataset_type
|
| 70 |
+
self.layers = nn.ModuleList()
|
| 71 |
+
self.first_branch = nn.ModuleList()
|
| 72 |
+
self.second_branch = nn.ModuleList()
|
| 73 |
+
self.order_type_embedder = nn.Embedding(3, 1)
|
| 74 |
+
self.norm_layer = BiN(num_features, seq_size)
|
| 75 |
+
self.emb_layer = nn.Linear(num_features, hidden_dim)
|
| 76 |
+
if is_sin_emb:
|
| 77 |
+
self.pos_encoder = sinusoidal_positional_embedding(seq_size, hidden_dim)
|
| 78 |
+
else:
|
| 79 |
+
self.pos_encoder = nn.Parameter(torch.randn(1, seq_size, hidden_dim))
|
| 80 |
+
|
| 81 |
+
for i in range(num_layers):
|
| 82 |
+
if i != num_layers-1:
|
| 83 |
+
self.layers.append(TransformerLayer(hidden_dim, num_heads, hidden_dim))
|
| 84 |
+
self.layers.append(TransformerLayer(seq_size, num_heads, seq_size))
|
| 85 |
+
else:
|
| 86 |
+
self.layers.append(TransformerLayer(hidden_dim, num_heads, hidden_dim//4))
|
| 87 |
+
self.layers.append(TransformerLayer(seq_size, num_heads, seq_size//4))
|
| 88 |
+
self.att_temporal = []
|
| 89 |
+
self.att_feature = []
|
| 90 |
+
self.mean_att_distance_temporal = []
|
| 91 |
+
total_dim = (hidden_dim//4)*(seq_size//4)
|
| 92 |
+
self.final_layers = nn.ModuleList()
|
| 93 |
+
while total_dim > 128:
|
| 94 |
+
self.final_layers.append(nn.Linear(total_dim, total_dim//4))
|
| 95 |
+
self.final_layers.append(nn.GELU())
|
| 96 |
+
total_dim = total_dim//4
|
| 97 |
+
self.final_layers.append(nn.Linear(total_dim, 3))
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def forward(self, input, store_att=False):
|
| 101 |
+
if self.dataset_type == "LOBSTER":
|
| 102 |
+
continuous_features = torch.cat([input[:, :, :41], input[:, :, 42:]], dim=2)
|
| 103 |
+
order_type = input[:, :, 41].long()
|
| 104 |
+
order_type_emb = self.order_type_embedder(order_type).detach()
|
| 105 |
+
x = torch.cat([continuous_features, order_type_emb], dim=2)
|
| 106 |
+
else:
|
| 107 |
+
x = input
|
| 108 |
+
x = rearrange(x, 'b s f -> b f s')
|
| 109 |
+
x = self.norm_layer(x)
|
| 110 |
+
x = rearrange(x, 'b f s -> b s f')
|
| 111 |
+
x = self.emb_layer(x)
|
| 112 |
+
x = x[:] + self.pos_encoder
|
| 113 |
+
mean_att_distance_temporal = np.zeros((self.num_layers, self.num_heads))
|
| 114 |
+
att_max_temporal = np.zeros((self.num_layers, 2, self.num_heads, self.seq_size))
|
| 115 |
+
att_max_feature = np.zeros((self.num_layers-1, 2, self.num_heads, self.hidden_dim))
|
| 116 |
+
att_temporal = np.zeros((self.num_layers, self.num_heads, self.seq_size, self.seq_size))
|
| 117 |
+
att_feature = np.zeros((self.num_layers-1, self.num_heads, self.hidden_dim, self.hidden_dim))
|
| 118 |
+
for i in range(len(self.layers)):
|
| 119 |
+
x, att = self.layers[i](x)
|
| 120 |
+
att = att.detach()
|
| 121 |
+
x = x.permute(0, 2, 1)
|
| 122 |
+
if store_att:
|
| 123 |
+
if i % 2 == 0:
|
| 124 |
+
att_temporal[i//2] = att[0].cpu().numpy()
|
| 125 |
+
values, indices = att[0].max(dim=2)
|
| 126 |
+
mean_att_distance_temporal[i//2] = compute_mean_att_distance(att[0])
|
| 127 |
+
att_max_temporal[i//2, 0] = indices.cpu().numpy()
|
| 128 |
+
att_max_temporal[i//2, 1] = values.cpu().numpy()
|
| 129 |
+
elif i % 2 == 1 and i != len(self.layers)-1:
|
| 130 |
+
att_feature[i//2] = att[0].cpu().numpy()
|
| 131 |
+
values, indices = att[0].max(dim=2)
|
| 132 |
+
att_max_feature[i//2, 0] = indices.cpu().numpy()
|
| 133 |
+
att_max_feature[i//2, 1] = values.cpu().numpy()
|
| 134 |
+
self.mean_att_distance_temporal.append(mean_att_distance_temporal)
|
| 135 |
+
if store_att:
|
| 136 |
+
self.att_temporal.append(att_max_temporal)
|
| 137 |
+
self.att_feature.append(att_max_feature)
|
| 138 |
+
x = rearrange(x, 'b s f -> b (f s) 1')
|
| 139 |
+
x = x.reshape(x.shape[0], -1)
|
| 140 |
+
for layer in self.final_layers:
|
| 141 |
+
x = layer(x)
|
| 142 |
+
return x, att_temporal, att_feature
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def sinusoidal_positional_embedding(token_sequence_size, token_embedding_dim, n=10000.0):
|
| 146 |
+
|
| 147 |
+
if token_embedding_dim % 2 != 0:
|
| 148 |
+
raise ValueError("Sinusoidal positional embedding cannot apply to odd token embedding dim (got dim={:d})".format(token_embedding_dim))
|
| 149 |
+
|
| 150 |
+
T = token_sequence_size
|
| 151 |
+
d = token_embedding_dim
|
| 152 |
+
|
| 153 |
+
positions = torch.arange(0, T).unsqueeze_(1)
|
| 154 |
+
embeddings = torch.zeros(T, d)
|
| 155 |
+
|
| 156 |
+
denominators = torch.pow(n, 2*torch.arange(0, d//2)/d) # 10000^(2i/d_model), i is the index of embedding
|
| 157 |
+
embeddings[:, 0::2] = torch.sin(positions/denominators) # sin(pos/10000^(2i/d_model))
|
| 158 |
+
embeddings[:, 1::2] = torch.cos(positions/denominators) # cos(pos/10000^(2i/d_model))
|
| 159 |
+
|
| 160 |
+
return embeddings.to(cst.DEVICE, non_blocking=True)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def count_parameters(layer):
|
| 164 |
+
print(f"Number of parameters: {sum(p.numel() for p in layer.parameters() if p.requires_grad)}")
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def compute_mean_att_distance(att):
|
| 168 |
+
att_distances = np.zeros((att.shape[0], att.shape[1]))
|
| 169 |
+
for h in range(att.shape[0]):
|
| 170 |
+
for key in range(att.shape[2]):
|
| 171 |
+
for query in range(att.shape[1]):
|
| 172 |
+
distance = abs(query-key)
|
| 173 |
+
att_distances[h, key] += torch.abs(att[h, query, key]).cpu().item()*distance
|
| 174 |
+
mean_distances = att_distances.mean(axis=1)
|
| 175 |
+
return mean_distances
|
| 176 |
+
|
| 177 |
+
|
preprocessing/__pycache__/dataset.cpython-310.pyc
ADDED
|
Binary file (2.61 kB). View file
|
|
|
preprocessing/__pycache__/dataset.cpython-311.pyc
ADDED
|
Binary file (4.18 kB). View file
|
|
|
preprocessing/__pycache__/fi_2010.cpython-310.pyc
ADDED
|
Binary file (1.56 kB). View file
|
|
|
preprocessing/__pycache__/fi_2010.cpython-311.pyc
ADDED
|
Binary file (3.37 kB). View file
|
|
|
preprocessing/__pycache__/lobster.cpython-310.pyc
ADDED
|
Binary file (9.2 kB). View file
|
|
|
preprocessing/__pycache__/lobster.cpython-311.pyc
ADDED
|
Binary file (22.3 kB). View file
|
|
|
preprocessing/dataset.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from torch.utils import data
|
| 3 |
+
import pytorch_lightning as pl
|
| 4 |
+
from torch.utils.data import DataLoader
|
| 5 |
+
import numpy as np
|
| 6 |
+
import constants as cst
|
| 7 |
+
import time
|
| 8 |
+
from torch.utils import data
|
| 9 |
+
from utils.utils_data import one_hot_encoding_type, tanh_encoding_type
|
| 10 |
+
|
| 11 |
+
class Dataset(data.Dataset):
|
| 12 |
+
"""Characterizes a dataset for PyTorch"""
|
| 13 |
+
def __init__(self, x, y, seq_size):
|
| 14 |
+
"""Initialization"""
|
| 15 |
+
self.seq_size = seq_size
|
| 16 |
+
self.length = y.shape[0]
|
| 17 |
+
self.x = x
|
| 18 |
+
self.y = y
|
| 19 |
+
if type(self.x) == np.ndarray:
|
| 20 |
+
self.x = torch.from_numpy(x).float()
|
| 21 |
+
if type(self.y) == np.ndarray:
|
| 22 |
+
self.y = torch.from_numpy(y).long()
|
| 23 |
+
self.data = self.x
|
| 24 |
+
|
| 25 |
+
def __len__(self):
|
| 26 |
+
"""Denotes the total number of samples"""
|
| 27 |
+
return self.length
|
| 28 |
+
|
| 29 |
+
def __getitem__(self, i):
|
| 30 |
+
input = self.x[i:i+self.seq_size, :]
|
| 31 |
+
return input, self.y[i]
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class DataModule(pl.LightningDataModule):
|
| 38 |
+
def __init__(self, train_set, val_set, batch_size, test_batch_size, is_shuffle_train=True, test_set=None, num_workers=16):
|
| 39 |
+
super().__init__()
|
| 40 |
+
|
| 41 |
+
self.train_set = train_set
|
| 42 |
+
self.val_set = val_set
|
| 43 |
+
self.test_set = test_set
|
| 44 |
+
self.batch_size = batch_size
|
| 45 |
+
self.test_batch_size = test_batch_size
|
| 46 |
+
self.is_shuffle_train = is_shuffle_train
|
| 47 |
+
if train_set.data.device.type != cst.DEVICE: #this is true only when we are using a GPU but the data is still on the CPU
|
| 48 |
+
self.pin_memory = True
|
| 49 |
+
else:
|
| 50 |
+
self.pin_memory = False
|
| 51 |
+
self.num_workers = num_workers
|
| 52 |
+
|
| 53 |
+
def train_dataloader(self):
|
| 54 |
+
return DataLoader(
|
| 55 |
+
dataset=self.train_set,
|
| 56 |
+
batch_size=self.batch_size,
|
| 57 |
+
shuffle=self.is_shuffle_train,
|
| 58 |
+
pin_memory=self.pin_memory,
|
| 59 |
+
drop_last=False,
|
| 60 |
+
num_workers=self.num_workers,
|
| 61 |
+
persistent_workers=True
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
def val_dataloader(self):
|
| 65 |
+
return DataLoader(
|
| 66 |
+
dataset=self.val_set,
|
| 67 |
+
batch_size=self.test_batch_size,
|
| 68 |
+
shuffle=False,
|
| 69 |
+
pin_memory=self.pin_memory,
|
| 70 |
+
drop_last=False,
|
| 71 |
+
num_workers=self.num_workers,
|
| 72 |
+
persistent_workers=True
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def test_dataloader(self):
|
| 76 |
+
return DataLoader(
|
| 77 |
+
dataset=self.test_set,
|
| 78 |
+
batch_size=self.test_batch_size,
|
| 79 |
+
shuffle=False,
|
| 80 |
+
pin_memory=self.pin_memory,
|
| 81 |
+
drop_last=False,
|
| 82 |
+
num_workers=self.num_workers,
|
| 83 |
+
persistent_workers=True
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
|
preprocessing/fi_2010.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import constants as cst
|
| 3 |
+
import os
|
| 4 |
+
from torch.utils import data
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def fi_2010_load(path, seq_size, horizon, all_features):
|
| 9 |
+
dec_data = np.loadtxt(path + "/Train_Dst_NoAuction_ZScore_CF_7.txt")
|
| 10 |
+
full_train = dec_data[:, :int(dec_data.shape[1] * cst.SPLIT_RATES[0])]
|
| 11 |
+
full_val = dec_data[:, int(dec_data.shape[1] * cst.SPLIT_RATES[0]):]
|
| 12 |
+
dec_test1 = np.loadtxt(path + '/Test_Dst_NoAuction_ZScore_CF_7.txt')
|
| 13 |
+
dec_test2 = np.loadtxt(path + '/Test_Dst_NoAuction_ZScore_CF_8.txt')
|
| 14 |
+
dec_test3 = np.loadtxt(path + '/Test_Dst_NoAuction_ZScore_CF_9.txt')
|
| 15 |
+
full_test = np.hstack((dec_test1, dec_test2, dec_test3))
|
| 16 |
+
|
| 17 |
+
if horizon == 1:
|
| 18 |
+
tmp = 5
|
| 19 |
+
elif horizon == 2:
|
| 20 |
+
tmp = 4
|
| 21 |
+
elif horizon == 3:
|
| 22 |
+
tmp = 3
|
| 23 |
+
elif horizon == 5:
|
| 24 |
+
tmp = 2
|
| 25 |
+
elif horizon == 10:
|
| 26 |
+
tmp = 1
|
| 27 |
+
else:
|
| 28 |
+
raise ValueError("Horizon not found")
|
| 29 |
+
|
| 30 |
+
train_labels = full_train[-tmp, :].flatten()
|
| 31 |
+
val_labels = full_val[-tmp, :].flatten()
|
| 32 |
+
test_labels = full_test[-tmp, :].flatten()
|
| 33 |
+
|
| 34 |
+
train_labels = train_labels[seq_size-1:] - 1
|
| 35 |
+
val_labels = val_labels[seq_size-1:] - 1
|
| 36 |
+
test_labels = test_labels[seq_size-1:] - 1
|
| 37 |
+
if all_features:
|
| 38 |
+
train_input = full_train[:144, :].T
|
| 39 |
+
val_input = full_val[:144, :].T
|
| 40 |
+
test_input = full_test[:144, :].T
|
| 41 |
+
else:
|
| 42 |
+
train_input = full_train[:40, :].T
|
| 43 |
+
val_input = full_val[:40, :].T
|
| 44 |
+
test_input = full_test[:40, :].T
|
| 45 |
+
train_input = torch.from_numpy(train_input).float()
|
| 46 |
+
train_labels = torch.from_numpy(train_labels).long()
|
| 47 |
+
val_input = torch.from_numpy(val_input).float()
|
| 48 |
+
val_labels = torch.from_numpy(val_labels).long()
|
| 49 |
+
test_input = torch.from_numpy(test_input).float()
|
| 50 |
+
test_labels = torch.from_numpy(test_labels).long()
|
| 51 |
+
return train_input, train_labels, val_input, val_labels, test_input, test_labels
|
| 52 |
+
|
| 53 |
+
|
preprocessing/lobster.py
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from utils.utils_data import z_score_orderbook, normalize_messages, preprocess_data, one_hot_encoding_type
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import constants as cst
|
| 7 |
+
from torch.utils import data
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def lobster_load(path, all_features, len_smooth, h, seq_size):
|
| 11 |
+
set = np.load(path)
|
| 12 |
+
if h == 10:
|
| 13 |
+
tmp = 5
|
| 14 |
+
if h == 20:
|
| 15 |
+
tmp = 4
|
| 16 |
+
elif h == 50:
|
| 17 |
+
tmp = 3
|
| 18 |
+
elif h == 100:
|
| 19 |
+
tmp = 2
|
| 20 |
+
elif h == 200:
|
| 21 |
+
tmp = 1
|
| 22 |
+
labels = set[seq_size-len_smooth:, -tmp]
|
| 23 |
+
labels = labels[np.isfinite(labels)]
|
| 24 |
+
labels = torch.from_numpy(labels).long()
|
| 25 |
+
if all_features:
|
| 26 |
+
input = set[:, cst.LEN_ORDER:cst.LEN_ORDER + 40]
|
| 27 |
+
orders = set[:, :cst.LEN_ORDER]
|
| 28 |
+
input = torch.from_numpy(input).float()
|
| 29 |
+
orders = torch.from_numpy(orders).float()
|
| 30 |
+
input = torch.cat((input, orders), dim=1)
|
| 31 |
+
else:
|
| 32 |
+
input = set[:, cst.LEN_ORDER:cst.LEN_ORDER + 40]
|
| 33 |
+
input = torch.from_numpy(input).float()
|
| 34 |
+
|
| 35 |
+
return input, labels
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def labeling(X, len, h, stock):
|
| 39 |
+
# X is the orderbook
|
| 40 |
+
# len is the time window smoothing length
|
| 41 |
+
# h is the prediction horizon
|
| 42 |
+
[N, D] = X.shape
|
| 43 |
+
|
| 44 |
+
if h < len:
|
| 45 |
+
len = h
|
| 46 |
+
# Calculate previous and future mid-prices for all relevant indices
|
| 47 |
+
previous_ask_prices = np.lib.stride_tricks.sliding_window_view(X[:, 0], window_shape=len)[:-h]
|
| 48 |
+
previous_bid_prices = np.lib.stride_tricks.sliding_window_view(X[:, 2], window_shape=len)[:-h]
|
| 49 |
+
future_ask_prices = np.lib.stride_tricks.sliding_window_view(X[:, 0], window_shape=len)[h:]
|
| 50 |
+
future_bid_prices = np.lib.stride_tricks.sliding_window_view(X[:, 2], window_shape=len)[h:]
|
| 51 |
+
|
| 52 |
+
previous_mid_prices = (previous_ask_prices + previous_bid_prices) / 2
|
| 53 |
+
future_mid_prices = (future_ask_prices + future_bid_prices) / 2
|
| 54 |
+
|
| 55 |
+
previous_mid_prices = np.mean(previous_mid_prices, axis=1)
|
| 56 |
+
future_mid_prices = np.mean(future_mid_prices, axis=1)
|
| 57 |
+
|
| 58 |
+
# Compute percentage change
|
| 59 |
+
percentage_change = (future_mid_prices - previous_mid_prices) / previous_mid_prices
|
| 60 |
+
|
| 61 |
+
# alpha is the average percentage change of the stock
|
| 62 |
+
alpha = np.abs(percentage_change).mean() / 2
|
| 63 |
+
|
| 64 |
+
# alpha is the average spread of the stock in percentage of the mid-price
|
| 65 |
+
#alpha = (X[:, 0] - X[:, 2]).mean() / ((X[:, 0] + X[:, 2]) / 2).mean()
|
| 66 |
+
|
| 67 |
+
print(f"Alpha: {alpha}")
|
| 68 |
+
labels = np.where(percentage_change < -alpha, 2, np.where(percentage_change > alpha, 0, 1))
|
| 69 |
+
print(f"Number of labels: {np.unique(labels, return_counts=True)}")
|
| 70 |
+
print(f"Percentage of labels: {np.unique(labels, return_counts=True)[1] / labels.shape[0]}")
|
| 71 |
+
return labels
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class LOBSTERDataBuilder:
|
| 75 |
+
def __init__(
|
| 76 |
+
self,
|
| 77 |
+
stocks,
|
| 78 |
+
data_dir,
|
| 79 |
+
date_trading_days,
|
| 80 |
+
split_rates,
|
| 81 |
+
sampling_type,
|
| 82 |
+
sampling_time,
|
| 83 |
+
sampling_quantity,
|
| 84 |
+
):
|
| 85 |
+
self.n_lob_levels = cst.N_LOB_LEVELS
|
| 86 |
+
self.data_dir = data_dir
|
| 87 |
+
self.date_trading_days = date_trading_days
|
| 88 |
+
self.stocks = stocks
|
| 89 |
+
self.split_rates = split_rates
|
| 90 |
+
|
| 91 |
+
self.sampling_type = sampling_type
|
| 92 |
+
self.sampling_time = sampling_time
|
| 93 |
+
self.sampling_quantity = sampling_quantity
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def prepare_save_datasets(self):
|
| 97 |
+
for i in range(len(self.stocks)):
|
| 98 |
+
stock = self.stocks[i]
|
| 99 |
+
path = "{}/{}/{}_{}_{}".format(
|
| 100 |
+
self.data_dir,
|
| 101 |
+
stock,
|
| 102 |
+
stock,
|
| 103 |
+
self.date_trading_days[0],
|
| 104 |
+
self.date_trading_days[1],
|
| 105 |
+
)
|
| 106 |
+
self.dataframes = []
|
| 107 |
+
self._prepare_dataframes(path, stock)
|
| 108 |
+
|
| 109 |
+
path_where_to_save = "{}/{}".format(
|
| 110 |
+
self.data_dir,
|
| 111 |
+
stock,
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
self.train_input = pd.concat(self.dataframes[0], axis=1).values
|
| 115 |
+
self.val_input = pd.concat(self.dataframes[1], axis=1).values
|
| 116 |
+
self.test_input = pd.concat(self.dataframes[2], axis=1).values
|
| 117 |
+
self.train_set = pd.concat([pd.DataFrame(self.train_input), pd.DataFrame(self.train_labels_horizons)], axis=1).values
|
| 118 |
+
self.val_set = pd.concat([pd.DataFrame(self.val_input), pd.DataFrame(self.val_labels_horizons)], axis=1).values
|
| 119 |
+
self.test_set = pd.concat([pd.DataFrame(self.test_input), pd.DataFrame(self.test_labels_horizons)], axis=1).values
|
| 120 |
+
self._save(path_where_to_save)
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def _prepare_dataframes(self, path, stock):
|
| 124 |
+
COLUMNS_NAMES = {"orderbook": ["sell1", "vsell1", "buy1", "vbuy1",
|
| 125 |
+
"sell2", "vsell2", "buy2", "vbuy2",
|
| 126 |
+
"sell3", "vsell3", "buy3", "vbuy3",
|
| 127 |
+
"sell4", "vsell4", "buy4", "vbuy4",
|
| 128 |
+
"sell5", "vsell5", "buy5", "vbuy5",
|
| 129 |
+
"sell6", "vsell6", "buy6", "vbuy6",
|
| 130 |
+
"sell7", "vsell7", "buy7", "vbuy7",
|
| 131 |
+
"sell8", "vsell8", "buy8", "vbuy8",
|
| 132 |
+
"sell9", "vsell9", "buy9", "vbuy9",
|
| 133 |
+
"sell10", "vsell10", "buy10", "vbuy10"],
|
| 134 |
+
"message": ["time", "event_type", "order_id", "size", "price", "direction"]}
|
| 135 |
+
self.num_trading_days = len(os.listdir(path))//2
|
| 136 |
+
split_days = self._split_days()
|
| 137 |
+
split_days = [i * 2 for i in split_days]
|
| 138 |
+
self._create_dataframes_splitted(path, split_days, COLUMNS_NAMES)
|
| 139 |
+
# divide all the price, both of lob and messages, by 10000, to have dollars as unit
|
| 140 |
+
for i in range(len(self.dataframes)):
|
| 141 |
+
self.dataframes[i][0]["price"] = self.dataframes[i][0]["price"] / 10000
|
| 142 |
+
self.dataframes[i][1].loc[:, ::2] /= 10000
|
| 143 |
+
train_input = self.dataframes[0][1].values
|
| 144 |
+
val_input = self.dataframes[1][1].values
|
| 145 |
+
test_input = self.dataframes[2][1].values
|
| 146 |
+
#create a dataframe for the labels
|
| 147 |
+
for i in range(len(cst.LOBSTER_HORIZONS)):
|
| 148 |
+
if i == 0:
|
| 149 |
+
train_labels = labeling(train_input, cst.LEN_SMOOTH, cst.LOBSTER_HORIZONS[i], stock)
|
| 150 |
+
val_labels = labeling(val_input, cst.LEN_SMOOTH, cst.LOBSTER_HORIZONS[i], stock)
|
| 151 |
+
test_labels = labeling(test_input, cst.LEN_SMOOTH, cst.LOBSTER_HORIZONS[i], stock)
|
| 152 |
+
train_labels = np.concatenate([train_labels, np.full(shape=(train_input.shape[0] - train_labels.shape[0]), fill_value=np.inf)])
|
| 153 |
+
val_labels = np.concatenate([val_labels, np.full(shape=(val_input.shape[0] - val_labels.shape[0]), fill_value=np.inf)])
|
| 154 |
+
test_labels = np.concatenate([test_labels, np.full(shape=(test_input.shape[0] - test_labels.shape[0]), fill_value=np.inf)])
|
| 155 |
+
self.train_labels_horizons = pd.DataFrame(train_labels, columns=["label_h{}".format(cst.LOBSTER_HORIZONS[i])])
|
| 156 |
+
self.val_labels_horizons = pd.DataFrame(val_labels, columns=["label_h{}".format(cst.LOBSTER_HORIZONS[i])])
|
| 157 |
+
self.test_labels_horizons = pd.DataFrame(test_labels, columns=["label_h{}".format(cst.LOBSTER_HORIZONS[i])])
|
| 158 |
+
else:
|
| 159 |
+
train_labels = labeling(train_input, cst.LEN_SMOOTH, cst.LOBSTER_HORIZONS[i], stock)
|
| 160 |
+
val_labels = labeling(val_input, cst.LEN_SMOOTH, cst.LOBSTER_HORIZONS[i], stock)
|
| 161 |
+
test_labels = labeling(test_input, cst.LEN_SMOOTH, cst.LOBSTER_HORIZONS[i], stock)
|
| 162 |
+
train_labels = np.concatenate([train_labels, np.full(shape=(train_input.shape[0] - train_labels.shape[0]), fill_value=np.inf)])
|
| 163 |
+
val_labels = np.concatenate([val_labels, np.full(shape=(val_input.shape[0] - val_labels.shape[0]), fill_value=np.inf)])
|
| 164 |
+
test_labels = np.concatenate([test_labels, np.full(shape=(test_input.shape[0] - test_labels.shape[0]), fill_value=np.inf)])
|
| 165 |
+
self.train_labels_horizons["label_h{}".format(cst.LOBSTER_HORIZONS[i])] = train_labels
|
| 166 |
+
self.val_labels_horizons["label_h{}".format(cst.LOBSTER_HORIZONS[i])] = val_labels
|
| 167 |
+
self.test_labels_horizons["label_h{}".format(cst.LOBSTER_HORIZONS[i])] = test_labels
|
| 168 |
+
|
| 169 |
+
#self._sparse_representation()
|
| 170 |
+
|
| 171 |
+
# to conclude the preprocessing we normalize the dataframes
|
| 172 |
+
self._normalize_dataframes()
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
def _sparse_representation(self):
|
| 176 |
+
tick_size = 0.01
|
| 177 |
+
for i in range(len(self.dataframes)):
|
| 178 |
+
dense_repr = self.dataframes[i][1].values
|
| 179 |
+
sparse_repr = np.zeros((dense_repr.shape[0], dense_repr.shape[1] + 1))
|
| 180 |
+
for row in range(dense_repr.shape[0]):
|
| 181 |
+
sparse_pos_ask = 0
|
| 182 |
+
sparse_pos_bid = 0
|
| 183 |
+
mid_price = (dense_repr[row][0] + dense_repr[row][2]) / 2
|
| 184 |
+
sparse_repr[row][-1] = mid_price
|
| 185 |
+
for col in range(0, dense_repr.shape[1], 2):
|
| 186 |
+
if col == 0:
|
| 187 |
+
start_ask = dense_repr[row][col]
|
| 188 |
+
elif col == 2:
|
| 189 |
+
start_bid = dense_repr[row][col]
|
| 190 |
+
elif col % 4 == 0:
|
| 191 |
+
if sparse_pos_ask < (sparse_repr.shape[1]) - 1 / 2:
|
| 192 |
+
actual_ask = dense_repr[row][col]
|
| 193 |
+
for level in range(0, actual_ask-start_ask, -tick_size):
|
| 194 |
+
if sparse_pos_ask < (sparse_repr.shape[1]) - 1 / 2:
|
| 195 |
+
if level == actual_ask - start_ask - tick_size:
|
| 196 |
+
sparse_repr[row][sparse_pos_ask] = dense_repr[row][col+1]
|
| 197 |
+
else:
|
| 198 |
+
sparse_repr[row][sparse_pos_ask] = 0
|
| 199 |
+
sparse_pos_ask += 1
|
| 200 |
+
else:
|
| 201 |
+
break
|
| 202 |
+
start_ask = actual_ask
|
| 203 |
+
else:
|
| 204 |
+
continue
|
| 205 |
+
elif col % 4 == 2:
|
| 206 |
+
if sparse_pos_bid < (sparse_repr.shape[1]) - 1 / 2:
|
| 207 |
+
actual_bid = dense_repr[row][col]
|
| 208 |
+
for level in range(0, start_bid-actual_bid, -tick_size):
|
| 209 |
+
if sparse_pos_bid < (sparse_repr.shape[1]) - 1 / 2:
|
| 210 |
+
if level == start_bid - actual_bid - tick_size:
|
| 211 |
+
sparse_repr[row][sparse_pos_ask] = dense_repr[row][col+1]
|
| 212 |
+
else:
|
| 213 |
+
sparse_repr[row][sparse_pos_ask] = 0
|
| 214 |
+
sparse_pos_bid += 1
|
| 215 |
+
else:
|
| 216 |
+
break
|
| 217 |
+
start_bid = actual_bid
|
| 218 |
+
else:
|
| 219 |
+
continue
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def _create_dataframes_splitted(self, path, split_days, COLUMNS_NAMES):
|
| 223 |
+
# iterate over files in the data directory of self.STOCK_NAME
|
| 224 |
+
total_shape = 0
|
| 225 |
+
for i, filename in enumerate(sorted(os.listdir(path))):
|
| 226 |
+
f = os.path.join(path, filename)
|
| 227 |
+
print(f)
|
| 228 |
+
if os.path.isfile(f):
|
| 229 |
+
# then we create the df for the training set
|
| 230 |
+
if i < split_days[0]:
|
| 231 |
+
if (i % 2) == 0:
|
| 232 |
+
if i == 0:
|
| 233 |
+
train_messages = pd.read_csv(f, names=COLUMNS_NAMES["message"])
|
| 234 |
+
else:
|
| 235 |
+
train_message = pd.read_csv(f, names=COLUMNS_NAMES["message"])
|
| 236 |
+
|
| 237 |
+
else:
|
| 238 |
+
if i == 1:
|
| 239 |
+
train_orderbooks = pd.read_csv(f, names=COLUMNS_NAMES["orderbook"])
|
| 240 |
+
total_shape += train_orderbooks.shape[0]
|
| 241 |
+
train_orderbooks, train_messages = preprocess_data([train_messages, train_orderbooks], self.n_lob_levels, self.sampling_type, self.sampling_time, self.sampling_quantity)
|
| 242 |
+
if (len(train_orderbooks) != len(train_messages)):
|
| 243 |
+
raise ValueError("train_orderbook length is different than train_messages")
|
| 244 |
+
else:
|
| 245 |
+
train_orderbook = pd.read_csv(f, names=COLUMNS_NAMES["orderbook"])
|
| 246 |
+
total_shape += train_orderbook.shape[0]
|
| 247 |
+
train_orderbook, train_message = preprocess_data([train_message, train_orderbook], self.n_lob_levels, self.sampling_type, self.sampling_time, self.sampling_quantity)
|
| 248 |
+
train_messages = pd.concat([train_messages, train_message], axis=0)
|
| 249 |
+
train_orderbooks = pd.concat([train_orderbooks, train_orderbook], axis=0)
|
| 250 |
+
|
| 251 |
+
elif split_days[0] <= i < split_days[1]: # then we are creating the df for the validation set
|
| 252 |
+
if (i % 2) == 0:
|
| 253 |
+
if (i == split_days[0]):
|
| 254 |
+
self.dataframes.append([train_messages, train_orderbooks])
|
| 255 |
+
val_messages = pd.read_csv(f, names=COLUMNS_NAMES["message"])
|
| 256 |
+
else:
|
| 257 |
+
val_message = pd.read_csv(f, names=COLUMNS_NAMES["message"])
|
| 258 |
+
else:
|
| 259 |
+
if i == split_days[0] + 1:
|
| 260 |
+
val_orderbooks = pd.read_csv(f, names=COLUMNS_NAMES["orderbook"])
|
| 261 |
+
total_shape += val_orderbooks.shape[0]
|
| 262 |
+
val_orderbooks, val_messages = preprocess_data([val_messages, val_orderbooks], self.n_lob_levels, self.sampling_type, self.sampling_time, self.sampling_quantity)
|
| 263 |
+
if (len(val_orderbooks) != len(val_messages)):
|
| 264 |
+
raise ValueError("val_orderbook length is different than val_messages")
|
| 265 |
+
else:
|
| 266 |
+
val_orderbook = pd.read_csv(f, names=COLUMNS_NAMES["orderbook"])
|
| 267 |
+
total_shape += val_orderbook.shape[0]
|
| 268 |
+
val_orderbook, val_message = preprocess_data([val_message, val_orderbook], self.n_lob_levels, self.sampling_type, self.sampling_time, self.sampling_quantity)
|
| 269 |
+
val_messages = pd.concat([val_messages, val_message], axis=0)
|
| 270 |
+
val_orderbooks = pd.concat([val_orderbooks, val_orderbook], axis=0)
|
| 271 |
+
|
| 272 |
+
else: # then we are creating the df for the test set
|
| 273 |
+
|
| 274 |
+
if (i % 2) == 0:
|
| 275 |
+
if (i == split_days[1]):
|
| 276 |
+
self.dataframes.append([val_messages, val_orderbooks])
|
| 277 |
+
test_messages = pd.read_csv(f, names=COLUMNS_NAMES["message"])
|
| 278 |
+
else:
|
| 279 |
+
test_message = pd.read_csv(f, names=COLUMNS_NAMES["message"])
|
| 280 |
+
|
| 281 |
+
else:
|
| 282 |
+
if i == split_days[1] + 1:
|
| 283 |
+
test_orderbooks = pd.read_csv(f, names=COLUMNS_NAMES["orderbook"])
|
| 284 |
+
test_orderbooks, test_messages = preprocess_data([test_messages, test_orderbooks], self.n_lob_levels, self.sampling_type, self.sampling_time, self.sampling_quantity)
|
| 285 |
+
if (len(test_orderbooks) != len(test_messages)):
|
| 286 |
+
raise ValueError("test_orderbook length is different than test_messages")
|
| 287 |
+
else:
|
| 288 |
+
test_orderbook = pd.read_csv(f, names=COLUMNS_NAMES["orderbook"])
|
| 289 |
+
test_orderbook, test_message = preprocess_data([test_message, test_orderbook], self.n_lob_levels, self.sampling_type, self.sampling_time, self.sampling_quantity)
|
| 290 |
+
test_messages = pd.concat([test_messages, test_message], axis=0)
|
| 291 |
+
test_orderbooks = pd.concat([test_orderbooks, test_orderbook], axis=0)
|
| 292 |
+
else:
|
| 293 |
+
raise ValueError("File {} is not a file".format(f))
|
| 294 |
+
self.dataframes.append([test_messages, test_orderbooks])
|
| 295 |
+
print(f"Total shape of the orderbooks is {total_shape}")
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
def _normalize_dataframes(self):
|
| 299 |
+
#apply z score to orderbooks
|
| 300 |
+
for i in range(len(self.dataframes)):
|
| 301 |
+
if (i == 0):
|
| 302 |
+
self.dataframes[i][1], mean_size, mean_prices, std_size, std_prices = z_score_orderbook(self.dataframes[i][1])
|
| 303 |
+
else:
|
| 304 |
+
self.dataframes[i][1], _, _, _, _ = z_score_orderbook(self.dataframes[i][1], mean_size, mean_prices, std_size, std_prices)
|
| 305 |
+
|
| 306 |
+
#apply z-score to size and prices of messages with the statistics of the train set
|
| 307 |
+
for i in range(len(self.dataframes)):
|
| 308 |
+
if (i == 0):
|
| 309 |
+
self.dataframes[i][0], mean_size, mean_prices, std_size, std_prices, mean_time, std_time, mean_depth, std_depth = normalize_messages(self.dataframes[i][0])
|
| 310 |
+
else:
|
| 311 |
+
self.dataframes[i][0], _, _, _, _, _, _, _, _ = normalize_messages(self.dataframes[i][0], mean_size, mean_prices, std_size, std_prices, mean_time, std_time, mean_depth, std_depth)
|
| 312 |
+
|
| 313 |
+
def _save(self, path_where_to_save):
|
| 314 |
+
np.save(path_where_to_save + "/train.npy", self.train_set)
|
| 315 |
+
np.save(path_where_to_save + "/val.npy", self.val_set)
|
| 316 |
+
np.save(path_where_to_save + "/test.npy", self.test_set)
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def _split_days(self):
|
| 320 |
+
train = int(self.num_trading_days * self.split_rates[0])
|
| 321 |
+
val = int(self.num_trading_days * self.split_rates[1]) + train
|
| 322 |
+
test = int(self.num_trading_days * self.split_rates[2]) + val
|
| 323 |
+
print(f"There are {train} days for training, {val - train} days for validation and {test - val} days for testing")
|
| 324 |
+
return [train, val, test]
|
requirements.txt
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
einops
|
| 2 |
+
hydra-core
|
| 3 |
+
lightning
|
| 4 |
+
lion_pytorch
|
| 5 |
+
matplotlib
|
| 6 |
+
numpy
|
| 7 |
+
omegaconf
|
| 8 |
+
pandas
|
| 9 |
+
pytorch_lightning
|
| 10 |
+
Requests
|
| 11 |
+
scikit_learn
|
| 12 |
+
scipy
|
| 13 |
+
seaborn
|
| 14 |
+
torch
|
| 15 |
+
torch_ema
|
| 16 |
+
torchvision
|
| 17 |
+
transformers
|
| 18 |
+
wandb
|
| 19 |
+
|
run.py
ADDED
|
@@ -0,0 +1,434 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import lightning as L
|
| 2 |
+
import omegaconf
|
| 3 |
+
import torch
|
| 4 |
+
from lightning.pytorch.loggers import WandbLogger
|
| 5 |
+
import wandb
|
| 6 |
+
from torch.utils.data import DataLoader
|
| 7 |
+
from lightning.pytorch.callbacks import TQDMProgressBar
|
| 8 |
+
from lightning.pytorch.callbacks.early_stopping import EarlyStopping
|
| 9 |
+
from config.config import Config
|
| 10 |
+
from models.engine import Engine
|
| 11 |
+
from preprocessing.fi_2010 import fi_2010_load
|
| 12 |
+
from preprocessing.lobster import lobster_load
|
| 13 |
+
from preprocessing.dataset import Dataset, DataModule
|
| 14 |
+
import constants as cst
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def run(config: Config, accelerator, model=None):
|
| 18 |
+
run_name = ""
|
| 19 |
+
for param in config.model.keys():
|
| 20 |
+
value = config.model[param]
|
| 21 |
+
if param == "hyperparameters_sweep":
|
| 22 |
+
continue
|
| 23 |
+
if type(value) == omegaconf.dictconfig.DictConfig:
|
| 24 |
+
for key in value.keys():
|
| 25 |
+
run_name += str(key[:2]) + "_" + str(value[key]) + "_"
|
| 26 |
+
else:
|
| 27 |
+
run_name += str(param[:2]) + "_" + str(value.value) + "_"
|
| 28 |
+
run_name += f"seed_{config.experiment.seed}"
|
| 29 |
+
seq_size = config.model.hyperparameters_fixed["seq_size"]
|
| 30 |
+
horizon = config.experiment.horizon
|
| 31 |
+
training_stocks = config.experiment.training_stocks
|
| 32 |
+
dataset = config.experiment.dataset_type.value
|
| 33 |
+
if dataset == "LOBSTER":
|
| 34 |
+
config.experiment.filename_ckpt = f"{dataset}_{training_stocks}_seq_size_{seq_size}_horizon_{horizon}_{run_name}"
|
| 35 |
+
else:
|
| 36 |
+
config.experiment.filename_ckpt = f"{dataset}_seq_size_{seq_size}_horizon_{horizon}_{run_name}"
|
| 37 |
+
run_name = config.experiment.filename_ckpt
|
| 38 |
+
|
| 39 |
+
trainer = L.Trainer(
|
| 40 |
+
accelerator=accelerator,
|
| 41 |
+
precision=cst.PRECISION,
|
| 42 |
+
max_epochs=config.experiment.max_epochs,
|
| 43 |
+
callbacks=[
|
| 44 |
+
EarlyStopping(monitor="val_loss", mode="min", patience=2, verbose=True, min_delta=0.002),
|
| 45 |
+
TQDMProgressBar(refresh_rate=100)
|
| 46 |
+
],
|
| 47 |
+
num_sanity_val_steps=0,
|
| 48 |
+
detect_anomaly=False,
|
| 49 |
+
profiler=None,
|
| 50 |
+
check_val_every_n_epoch=1
|
| 51 |
+
)
|
| 52 |
+
train(config, trainer)
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def train(config: Config, trainer: L.Trainer, run=None):
|
| 56 |
+
print_setup(config)
|
| 57 |
+
dataset_type = config.experiment.dataset_type.value
|
| 58 |
+
seq_size = config.model.hyperparameters_fixed["seq_size"]
|
| 59 |
+
horizon = config.experiment.horizon
|
| 60 |
+
model_type = config.model.type
|
| 61 |
+
training_stocks = config.experiment.training_stocks
|
| 62 |
+
testing_stocks = config.experiment.testing_stocks
|
| 63 |
+
dataset_type = config.experiment.dataset_type.value
|
| 64 |
+
if dataset_type == "FI-2010":
|
| 65 |
+
path = cst.DATA_DIR + "/FI_2010"
|
| 66 |
+
train_input, train_labels, val_input, val_labels, test_input, test_labels = fi_2010_load(path, seq_size, horizon, config.model.hyperparameters_fixed["all_features"])
|
| 67 |
+
data_module = DataModule(
|
| 68 |
+
train_set=Dataset(train_input, train_labels, seq_size),
|
| 69 |
+
val_set=Dataset(val_input, val_labels, seq_size),
|
| 70 |
+
test_set=Dataset(test_input, test_labels, seq_size),
|
| 71 |
+
batch_size=config.experiment.batch_size,
|
| 72 |
+
test_batch_size=config.experiment.batch_size*4,
|
| 73 |
+
num_workers=4
|
| 74 |
+
)
|
| 75 |
+
test_loaders = [data_module.test_dataloader()]
|
| 76 |
+
else:
|
| 77 |
+
for i in range(len(training_stocks)):
|
| 78 |
+
if i == 0:
|
| 79 |
+
for j in range(2):
|
| 80 |
+
if j == 0:
|
| 81 |
+
path = cst.DATA_DIR + "/" + training_stocks[i] + "/train.npy"
|
| 82 |
+
train_input, train_labels = lobster_load(path, config.model.hyperparameters_fixed["all_features"], cst.LEN_SMOOTH, horizon, seq_size)
|
| 83 |
+
if j == 1:
|
| 84 |
+
path = cst.DATA_DIR + "/" + training_stocks[i] + "/val.npy"
|
| 85 |
+
val_input, val_labels = lobster_load(path, config.model.hyperparameters_fixed["all_features"], cst.LEN_SMOOTH, horizon, seq_size)
|
| 86 |
+
else:
|
| 87 |
+
for j in range(2):
|
| 88 |
+
if j == 0:
|
| 89 |
+
path = cst.DATA_DIR + "/" + training_stocks[i] + "/train.npy"
|
| 90 |
+
train_labels = torch.cat((train_labels, torch.zeros(seq_size+horizon-1, dtype=torch.long)), 0)
|
| 91 |
+
train_input_tmp, train_labels_tmp = lobster_load(path, config.model.hyperparameters_fixed["all_features"], cst.LEN_SMOOTH, horizon, seq_size)
|
| 92 |
+
train_input = torch.cat((train_input, train_input_tmp), 0)
|
| 93 |
+
train_labels = torch.cat((train_labels, train_labels_tmp), 0)
|
| 94 |
+
if j == 1:
|
| 95 |
+
path = cst.DATA_DIR + "/" + training_stocks[i] + "/val.npy"
|
| 96 |
+
val_labels = torch.cat((val_labels, torch.zeros(seq_size+horizon-1, dtype=torch.long)), 0)
|
| 97 |
+
val_input_tmp, val_labels_tmp = lobster_load(path, config.model.hyperparameters_fixed["all_features"], cst.LEN_SMOOTH, horizon, seq_size)
|
| 98 |
+
val_input = torch.cat((val_input, val_input_tmp), 0)
|
| 99 |
+
val_labels = torch.cat((val_labels, val_labels_tmp), 0)
|
| 100 |
+
test_loaders = []
|
| 101 |
+
for i in range(len(testing_stocks)):
|
| 102 |
+
path = cst.DATA_DIR + "/" + testing_stocks[i] + "/test.npy"
|
| 103 |
+
test_input, test_labels = lobster_load(path, config.model.hyperparameters_fixed["all_features"], cst.LEN_SMOOTH, horizon, seq_size)
|
| 104 |
+
test_set = Dataset(test_input, test_labels, seq_size)
|
| 105 |
+
test_dataloader = DataLoader(
|
| 106 |
+
dataset=test_set,
|
| 107 |
+
batch_size=config.experiment.batch_size*4,
|
| 108 |
+
shuffle=False,
|
| 109 |
+
pin_memory=True,
|
| 110 |
+
drop_last=False,
|
| 111 |
+
num_workers=4,
|
| 112 |
+
persistent_workers=True
|
| 113 |
+
)
|
| 114 |
+
test_loaders.append(test_dataloader)
|
| 115 |
+
train_set = Dataset(train_input, train_labels, seq_size)
|
| 116 |
+
val_set = Dataset(val_input, val_labels, seq_size)
|
| 117 |
+
counts_train = torch.unique(train_labels, return_counts=True)
|
| 118 |
+
counts_val = torch.unique(val_labels, return_counts=True)
|
| 119 |
+
print("Train set shape: ", train_input.shape)
|
| 120 |
+
print("Val set shape: ", val_input.shape)
|
| 121 |
+
print("Classes counts in train set: ", counts_train[1])
|
| 122 |
+
print("Classes counts in val set: ", counts_val[1])
|
| 123 |
+
print(f"Classes distribution in train set: up {counts_train[1][0]/train_labels.shape[0]} stat {counts_train[1][1]/train_labels.shape[0]} down {counts_train[1][2]/train_labels.shape[0]} ", )
|
| 124 |
+
print(f"Classes distribution in val set: up {counts_val[1][0]/val_labels.shape[0]} stat {counts_val[1][1]/val_labels.shape[0]} down {counts_val[1][2]/val_labels.shape[0]} ", )
|
| 125 |
+
data_module = DataModule(
|
| 126 |
+
train_set=train_set,
|
| 127 |
+
val_set=val_set,
|
| 128 |
+
batch_size=config.experiment.batch_size,
|
| 129 |
+
test_batch_size=config.experiment.batch_size*4,
|
| 130 |
+
num_workers=4
|
| 131 |
+
)
|
| 132 |
+
|
| 133 |
+
experiment_type = config.experiment.type
|
| 134 |
+
if "FINETUNING" in experiment_type or "EVALUATION" in experiment_type:
|
| 135 |
+
checkpoint = torch.load(config.experiment.checkpoint_reference, map_location=cst.DEVICE)
|
| 136 |
+
print("Loading model from checkpoint: ", config.experiment.checkpoint_reference)
|
| 137 |
+
lr = checkpoint["hyper_parameters"]["lr"]
|
| 138 |
+
filename_ckpt = checkpoint["hyper_parameters"]["filename_ckpt"]
|
| 139 |
+
hidden_dim = checkpoint["hyper_parameters"]["hidden_dim"]
|
| 140 |
+
num_layers = checkpoint["hyper_parameters"]["num_layers"]
|
| 141 |
+
optimizer = checkpoint["hyper_parameters"]["optimizer"]
|
| 142 |
+
model_type = checkpoint["hyper_parameters"]["model_type"]#.value
|
| 143 |
+
max_epochs = checkpoint["hyper_parameters"]["max_epochs"]
|
| 144 |
+
horizon = checkpoint["hyper_parameters"]["horizon"]
|
| 145 |
+
seq_size = checkpoint["hyper_parameters"]["seq_size"]
|
| 146 |
+
if model_type == "MLPLOB":
|
| 147 |
+
model = Engine.load_from_checkpoint(
|
| 148 |
+
config.experiment.checkpoint_reference,
|
| 149 |
+
seq_size=seq_size,
|
| 150 |
+
horizon=horizon,
|
| 151 |
+
max_epochs=max_epochs,
|
| 152 |
+
model_type=model_type,
|
| 153 |
+
is_wandb=config.experiment.is_wandb,
|
| 154 |
+
experiment_type=experiment_type,
|
| 155 |
+
lr=lr,
|
| 156 |
+
optimizer=optimizer,
|
| 157 |
+
filename_ckpt=filename_ckpt,
|
| 158 |
+
hidden_dim=hidden_dim,
|
| 159 |
+
num_layers=num_layers,
|
| 160 |
+
num_features=train_input.shape[1],
|
| 161 |
+
dataset_type=dataset_type,
|
| 162 |
+
map_location=cst.DEVICE,
|
| 163 |
+
)
|
| 164 |
+
elif model_type == "TLOB":
|
| 165 |
+
model = Engine.load_from_checkpoint(
|
| 166 |
+
config.experiment.checkpoint_reference,
|
| 167 |
+
seq_size=seq_size,
|
| 168 |
+
horizon=horizon,
|
| 169 |
+
max_epochs=max_epochs,
|
| 170 |
+
model_type=model_type,
|
| 171 |
+
is_wandb=config.experiment.is_wandb,
|
| 172 |
+
experiment_type=experiment_type,
|
| 173 |
+
lr=lr,
|
| 174 |
+
optimizer=optimizer,
|
| 175 |
+
filename_ckpt=filename_ckpt,
|
| 176 |
+
hidden_dim=hidden_dim,
|
| 177 |
+
num_layers=num_layers,
|
| 178 |
+
num_features=train_input.shape[1],
|
| 179 |
+
dataset_type=dataset_type,
|
| 180 |
+
num_heads=checkpoint["hyper_parameters"]["num_heads"],
|
| 181 |
+
is_sin_emb=checkpoint["hyper_parameters"]["is_sin_emb"],
|
| 182 |
+
map_location=cst.DEVICE,
|
| 183 |
+
len_test_dataloader=len(test_loaders[0])
|
| 184 |
+
)
|
| 185 |
+
elif model_type == "BINCTABL":
|
| 186 |
+
model = Engine.load_from_checkpoint(
|
| 187 |
+
config.experiment.checkpoint_reference,
|
| 188 |
+
seq_size=seq_size,
|
| 189 |
+
horizon=horizon,
|
| 190 |
+
max_epochs=max_epochs,
|
| 191 |
+
model_type=model_type,
|
| 192 |
+
is_wandb=config.experiment.is_wandb,
|
| 193 |
+
experiment_type=experiment_type,
|
| 194 |
+
lr=lr,
|
| 195 |
+
optimizer=optimizer,
|
| 196 |
+
filename_ckpt=filename_ckpt,
|
| 197 |
+
num_features=train_input.shape[1],
|
| 198 |
+
dataset_type=dataset_type,
|
| 199 |
+
map_location=cst.DEVICE,
|
| 200 |
+
len_test_dataloader=len(test_loaders[0])
|
| 201 |
+
)
|
| 202 |
+
elif model_type == "DEEPLOB":
|
| 203 |
+
model = Engine.load_from_checkpoint(
|
| 204 |
+
config.experiment.checkpoint_reference,
|
| 205 |
+
seq_size=seq_size,
|
| 206 |
+
horizon=horizon,
|
| 207 |
+
max_epochs=max_epochs,
|
| 208 |
+
model_type=model_type,
|
| 209 |
+
is_wandb=config.experiment.is_wandb,
|
| 210 |
+
experiment_type=experiment_type,
|
| 211 |
+
lr=lr,
|
| 212 |
+
optimizer=optimizer,
|
| 213 |
+
filename_ckpt=filename_ckpt,
|
| 214 |
+
num_features=train_input.shape[1],
|
| 215 |
+
dataset_type=dataset_type,
|
| 216 |
+
map_location=cst.DEVICE,
|
| 217 |
+
len_test_dataloader=len(test_loaders[0])
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
else:
|
| 221 |
+
if model_type == cst.ModelType.MLPLOB:
|
| 222 |
+
model = Engine(
|
| 223 |
+
seq_size=seq_size,
|
| 224 |
+
horizon=horizon,
|
| 225 |
+
max_epochs=config.experiment.max_epochs,
|
| 226 |
+
model_type=config.model.type.value,
|
| 227 |
+
is_wandb=config.experiment.is_wandb,
|
| 228 |
+
experiment_type=experiment_type,
|
| 229 |
+
lr=config.model.hyperparameters_fixed["lr"],
|
| 230 |
+
optimizer=config.experiment.optimizer,
|
| 231 |
+
filename_ckpt=config.experiment.filename_ckpt,
|
| 232 |
+
hidden_dim=config.model.hyperparameters_fixed["hidden_dim"],
|
| 233 |
+
num_layers=config.model.hyperparameters_fixed["num_layers"],
|
| 234 |
+
num_features=train_input.shape[1],
|
| 235 |
+
dataset_type=dataset_type,
|
| 236 |
+
len_test_dataloader=len(test_loaders[0])
|
| 237 |
+
)
|
| 238 |
+
elif model_type == cst.ModelType.TLOB:
|
| 239 |
+
model = Engine(
|
| 240 |
+
seq_size=seq_size,
|
| 241 |
+
horizon=horizon,
|
| 242 |
+
max_epochs=config.experiment.max_epochs,
|
| 243 |
+
model_type=config.model.type.value,
|
| 244 |
+
is_wandb=config.experiment.is_wandb,
|
| 245 |
+
experiment_type=experiment_type,
|
| 246 |
+
lr=config.model.hyperparameters_fixed["lr"],
|
| 247 |
+
optimizer=config.experiment.optimizer,
|
| 248 |
+
filename_ckpt=config.experiment.filename_ckpt,
|
| 249 |
+
hidden_dim=config.model.hyperparameters_fixed["hidden_dim"],
|
| 250 |
+
num_layers=config.model.hyperparameters_fixed["num_layers"],
|
| 251 |
+
num_features=train_input.shape[1],
|
| 252 |
+
dataset_type=dataset_type,
|
| 253 |
+
num_heads=config.model.hyperparameters_fixed["num_heads"],
|
| 254 |
+
is_sin_emb=config.model.hyperparameters_fixed["is_sin_emb"],
|
| 255 |
+
len_test_dataloader=len(test_loaders[0])
|
| 256 |
+
)
|
| 257 |
+
elif model_type == cst.ModelType.BINCTABL:
|
| 258 |
+
model = Engine(
|
| 259 |
+
seq_size=seq_size,
|
| 260 |
+
horizon=horizon,
|
| 261 |
+
max_epochs=config.experiment.max_epochs,
|
| 262 |
+
model_type=config.model.type.value,
|
| 263 |
+
is_wandb=config.experiment.is_wandb,
|
| 264 |
+
experiment_type=experiment_type,
|
| 265 |
+
lr=config.model.hyperparameters_fixed["lr"],
|
| 266 |
+
optimizer=config.experiment.optimizer,
|
| 267 |
+
filename_ckpt=config.experiment.filename_ckpt,
|
| 268 |
+
num_features=train_input.shape[1],
|
| 269 |
+
dataset_type=dataset_type,
|
| 270 |
+
len_test_dataloader=len(test_loaders[0])
|
| 271 |
+
)
|
| 272 |
+
elif model_type == cst.ModelType.DEEPLOB:
|
| 273 |
+
model = Engine(
|
| 274 |
+
seq_size=seq_size,
|
| 275 |
+
horizon=horizon,
|
| 276 |
+
max_epochs=config.experiment.max_epochs,
|
| 277 |
+
model_type=config.model.type.value,
|
| 278 |
+
is_wandb=config.experiment.is_wandb,
|
| 279 |
+
experiment_type=experiment_type,
|
| 280 |
+
lr=config.model.hyperparameters_fixed["lr"],
|
| 281 |
+
optimizer=config.experiment.optimizer,
|
| 282 |
+
filename_ckpt=config.experiment.filename_ckpt,
|
| 283 |
+
num_features=train_input.shape[1],
|
| 284 |
+
dataset_type=dataset_type,
|
| 285 |
+
len_test_dataloader=len(test_loaders[0])
|
| 286 |
+
)
|
| 287 |
+
|
| 288 |
+
print("total number of parameters: ", sum(p.numel() for p in model.parameters()))
|
| 289 |
+
train_dataloader, val_dataloader = data_module.train_dataloader(), data_module.val_dataloader()
|
| 290 |
+
|
| 291 |
+
if "TRAINING" in experiment_type or "FINETUNING" in experiment_type:
|
| 292 |
+
trainer.fit(model, train_dataloader, val_dataloader)
|
| 293 |
+
best_model_path = model.last_path_ckpt
|
| 294 |
+
print("Best model path: ", best_model_path)
|
| 295 |
+
try:
|
| 296 |
+
best_model = Engine.load_from_checkpoint(best_model_path, map_location=cst.DEVICE)
|
| 297 |
+
except:
|
| 298 |
+
print("no checkpoints has been saved, selecting the last model")
|
| 299 |
+
best_model = model
|
| 300 |
+
best_model.experiment_type = "EVALUATION"
|
| 301 |
+
for i in range(len(test_loaders)):
|
| 302 |
+
test_dataloader = test_loaders[i]
|
| 303 |
+
output = trainer.test(best_model, test_dataloader)
|
| 304 |
+
if run is not None and dataset_type == "LOBSTER":
|
| 305 |
+
run.log({f"f1 {testing_stocks[i]} best": output[0]["f1_score"]}, commit=False)
|
| 306 |
+
elif run is not None and dataset_type == "FI-2010":
|
| 307 |
+
run.log({f"f1 FI-2010 ": output[0]["f1_score"]}, commit=False)
|
| 308 |
+
else:
|
| 309 |
+
for i in range(len(test_loaders)):
|
| 310 |
+
test_dataloader = test_loaders[i]
|
| 311 |
+
output = trainer.test(model, test_dataloader)
|
| 312 |
+
if run is not None and dataset_type == "LOBSTER":
|
| 313 |
+
run.log({f"f1 {testing_stocks[i]} best": output[0]["f1_score"]}, commit=False)
|
| 314 |
+
elif run is not None and dataset_type == "FI-2010":
|
| 315 |
+
run.log({f"f1 FI-2010 ": output[0]["f1_score"]}, commit=False)
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def run_wandb(config: Config, accelerator):
|
| 320 |
+
def wandb_sweep_callback():
|
| 321 |
+
wandb_logger = WandbLogger(project=cst.PROJECT_NAME, log_model=False, save_dir=cst.DIR_SAVED_MODEL)
|
| 322 |
+
run_name = None
|
| 323 |
+
if not config.experiment.is_sweep:
|
| 324 |
+
run_name = ""
|
| 325 |
+
for param in config.model.keys():
|
| 326 |
+
value = config.model[param]
|
| 327 |
+
if param == "hyperparameters_sweep":
|
| 328 |
+
continue
|
| 329 |
+
if type(value) == omegaconf.dictconfig.DictConfig:
|
| 330 |
+
for key in value.keys():
|
| 331 |
+
run_name += str(key[:2]) + "_" + str(value[key]) + "_"
|
| 332 |
+
else:
|
| 333 |
+
run_name += str(param[:2]) + "_" + str(value.value) + "_"
|
| 334 |
+
|
| 335 |
+
run = wandb.init(project=cst.PROJECT_NAME, name=run_name, entity="") # set entity to your wandb username
|
| 336 |
+
|
| 337 |
+
if config.experiment.is_sweep:
|
| 338 |
+
model_params = run.config
|
| 339 |
+
else:
|
| 340 |
+
model_params = config.model.hyperparameters_fixed
|
| 341 |
+
wandb_instance_name = ""
|
| 342 |
+
for param in config.model.hyperparameters_fixed.keys():
|
| 343 |
+
if param in model_params:
|
| 344 |
+
config.model.hyperparameters_fixed[param] = model_params[param]
|
| 345 |
+
wandb_instance_name += str(param) + "_" + str(model_params[param]) + "_"
|
| 346 |
+
|
| 347 |
+
#wandb_instance_name += f"seed_{cst.SEED}"
|
| 348 |
+
|
| 349 |
+
run.name = wandb_instance_name
|
| 350 |
+
seq_size = config.model.hyperparameters_fixed["seq_size"]
|
| 351 |
+
horizon = config.experiment.horizon
|
| 352 |
+
dataset = config.experiment.dataset_type.value
|
| 353 |
+
training_stocks = config.experiment.training_stocks
|
| 354 |
+
if dataset == "LOBSTER":
|
| 355 |
+
config.experiment.filename_ckpt = f"{dataset}_{training_stocks}_seq_size_{seq_size}_horizon_{horizon}_{run_name}"
|
| 356 |
+
else:
|
| 357 |
+
config.experiment.filename_ckpt = f"{dataset}_seq_size_{seq_size}_horizon_{horizon}_{run_name}"
|
| 358 |
+
wandb_instance_name = config.experiment.filename_ckpt
|
| 359 |
+
|
| 360 |
+
trainer = L.Trainer(
|
| 361 |
+
accelerator=accelerator,
|
| 362 |
+
precision=cst.PRECISION,
|
| 363 |
+
max_epochs=config.experiment.max_epochs,
|
| 364 |
+
callbacks=[
|
| 365 |
+
EarlyStopping(monitor="val_loss", mode="min", patience=2, verbose=True, min_delta=0.002),
|
| 366 |
+
TQDMProgressBar(refresh_rate=1000)
|
| 367 |
+
],
|
| 368 |
+
num_sanity_val_steps=0,
|
| 369 |
+
logger=wandb_logger,
|
| 370 |
+
detect_anomaly=False,
|
| 371 |
+
check_val_every_n_epoch=1,
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
# log simulation details in WANDB console
|
| 375 |
+
run.log({"model": config.model.type.value}, commit=False)
|
| 376 |
+
run.log({"dataset": config.experiment.dataset_type.value}, commit=False)
|
| 377 |
+
run.log({"seed": config.experiment.seed}, commit=False)
|
| 378 |
+
run.log({"all_features": config.model.hyperparameters_fixed["all_features"]}, commit=False)
|
| 379 |
+
if config.experiment.dataset_type == cst.Dataset.LOBSTER:
|
| 380 |
+
for i in range(len(config.experiment.training_stocks)):
|
| 381 |
+
run.log({f"training stock{i}": config.experiment.training_stocks[i]}, commit=False)
|
| 382 |
+
for i in range(len(config.experiment.testing_stocks)):
|
| 383 |
+
run.log({f"testing stock{i}": config.experiment.testing_stocks[i]}, commit=False)
|
| 384 |
+
run.log({"sampling_type": config.experiment.sampling_type}, commit=False)
|
| 385 |
+
if config.experiment.sampling_type == "time":
|
| 386 |
+
run.log({"sampling_time": config.experiment.sampling_time}, commit=False)
|
| 387 |
+
else:
|
| 388 |
+
run.log({"sampling_quantity": config.experiment.sampling_quantity}, commit=False)
|
| 389 |
+
train(config, trainer, run)
|
| 390 |
+
run.finish()
|
| 391 |
+
|
| 392 |
+
return wandb_sweep_callback
|
| 393 |
+
|
| 394 |
+
|
| 395 |
+
def sweep_init(config: Config):
|
| 396 |
+
# put your wandb key here
|
| 397 |
+
wandb.login()
|
| 398 |
+
parameters = {}
|
| 399 |
+
for key in config.model.hyperparameters_sweep.keys():
|
| 400 |
+
parameters[key] = {'values': list(config.model.hyperparameters_sweep[key])}
|
| 401 |
+
sweep_config = {
|
| 402 |
+
'method': 'grid',
|
| 403 |
+
'metric': {
|
| 404 |
+
'goal': 'minimize',
|
| 405 |
+
'name': 'val_loss'
|
| 406 |
+
},
|
| 407 |
+
'early_terminate': {
|
| 408 |
+
'type': 'hyperband',
|
| 409 |
+
'min_iter': 3,
|
| 410 |
+
'eta': 1.5
|
| 411 |
+
},
|
| 412 |
+
'run_cap': 100,
|
| 413 |
+
'parameters': {**parameters}
|
| 414 |
+
}
|
| 415 |
+
return sweep_config
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
def print_setup(config: Config):
|
| 419 |
+
print("Model type: ", config.model.type)
|
| 420 |
+
print("Dataset: ", config.experiment.dataset_type)
|
| 421 |
+
print("Seed: ", config.experiment.seed)
|
| 422 |
+
print("Sequence size: ", config.model.hyperparameters_fixed["seq_size"])
|
| 423 |
+
print("Horizon: ", config.experiment.horizon)
|
| 424 |
+
print("All features: ", config.model.hyperparameters_fixed["all_features"])
|
| 425 |
+
print("Is data preprocessed: ", config.experiment.is_data_preprocessed)
|
| 426 |
+
print("Is wandb: ", config.experiment.is_wandb)
|
| 427 |
+
print("Is sweep: ", config.experiment.is_sweep)
|
| 428 |
+
print(config.experiment.type)
|
| 429 |
+
print("Is debug: ", config.experiment.is_debug)
|
| 430 |
+
if config.experiment.dataset_type == cst.Dataset.LOBSTER:
|
| 431 |
+
print("Training stocks: ", config.experiment.training_stocks)
|
| 432 |
+
print("Testing stocks: ", config.experiment.testing_stocks)
|
| 433 |
+
|
| 434 |
+
|
tslaintc.png
ADDED
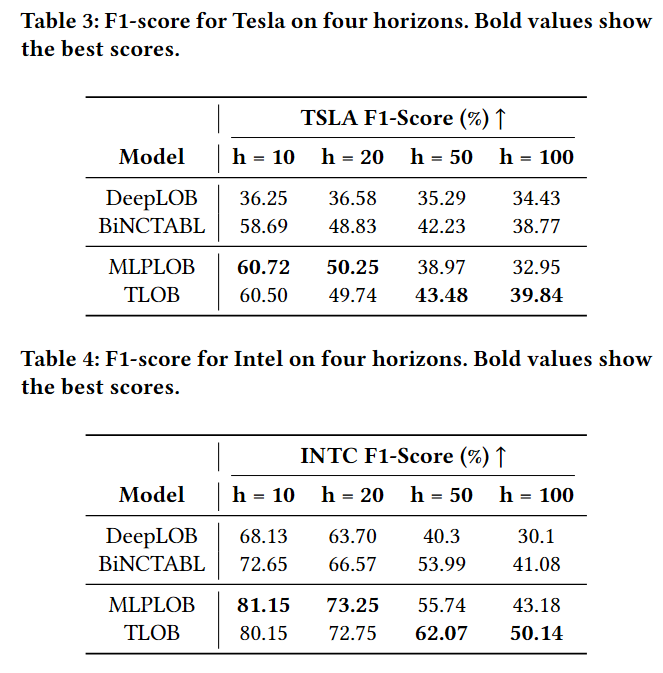
|
utils/__pycache__/utils_data.cpython-311.pyc
ADDED
|
Binary file (12.5 kB). View file
|
|
|
utils/__pycache__/utils_model.cpython-310.pyc
ADDED
|
Binary file (827 Bytes). View file
|
|
|
utils/__pycache__/utils_model.cpython-311.pyc
ADDED
|
Binary file (1.2 kB). View file
|
|
|
utils/utils_data.py
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import numpy as np
|
| 3 |
+
import os
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import pandas
|
| 7 |
+
import constants as cst
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def z_score_orderbook(data, mean_size=None, mean_prices=None, std_size=None, std_prices=None):
|
| 11 |
+
""" DONE: remember to use the mean/std of the training set, to z-normalize the test set. """
|
| 12 |
+
if (mean_size is None) or (std_size is None):
|
| 13 |
+
mean_size = data.iloc[:, 1::2].stack().mean()
|
| 14 |
+
std_size = data.iloc[:, 1::2].stack().std()
|
| 15 |
+
|
| 16 |
+
#do the same thing for prices
|
| 17 |
+
if (mean_prices is None) or (std_prices is None):
|
| 18 |
+
mean_prices = data.iloc[:, 0::2].stack().mean() #price
|
| 19 |
+
std_prices = data.iloc[:, 0::2].stack().std() #price
|
| 20 |
+
|
| 21 |
+
# apply the z score to the original data using .loc with explicit float cast
|
| 22 |
+
price_cols = data.columns[0::2]
|
| 23 |
+
size_cols = data.columns[1::2]
|
| 24 |
+
|
| 25 |
+
#apply the z score to the original data
|
| 26 |
+
for col in size_cols:
|
| 27 |
+
data[col] = data[col].astype("float64")
|
| 28 |
+
data[col] = (data[col] - mean_size) / std_size
|
| 29 |
+
|
| 30 |
+
for col in price_cols:
|
| 31 |
+
data[col] = data[col].astype("float64")
|
| 32 |
+
data[col] = (data[col] - mean_prices) / std_prices
|
| 33 |
+
|
| 34 |
+
# check if there are null values, then raise value error
|
| 35 |
+
if data.isnull().values.any():
|
| 36 |
+
raise ValueError("data contains null value")
|
| 37 |
+
|
| 38 |
+
return data, mean_size, mean_prices, std_size, std_prices
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def normalize_messages(data, mean_size=None, mean_prices=None, std_size=None, std_prices=None, mean_time=None, std_time=None, mean_depth=None, std_depth=None):
|
| 42 |
+
|
| 43 |
+
#apply z score to prices and size column
|
| 44 |
+
if (mean_size is None) or (std_size is None):
|
| 45 |
+
mean_size = data["size"].mean()
|
| 46 |
+
std_size = data["size"].std()
|
| 47 |
+
|
| 48 |
+
if (mean_prices is None) or (std_prices is None):
|
| 49 |
+
mean_prices = data["price"].mean()
|
| 50 |
+
std_prices = data["price"].std()
|
| 51 |
+
|
| 52 |
+
if (mean_time is None) or (std_time is None):
|
| 53 |
+
mean_time = data["time"].mean()
|
| 54 |
+
std_time = data["time"].std()
|
| 55 |
+
|
| 56 |
+
if (mean_depth is None) or (std_depth is None):
|
| 57 |
+
mean_depth = data["depth"].mean()
|
| 58 |
+
std_depth = data["depth"].std()
|
| 59 |
+
|
| 60 |
+
#apply the z score to the original data
|
| 61 |
+
data["time"] = (data["time"] - mean_time) / std_time
|
| 62 |
+
data["size"] = (data["size"] - mean_size) / std_size
|
| 63 |
+
data["price"] = (data["price"] - mean_prices) / std_prices
|
| 64 |
+
data["depth"] = (data["depth"] - mean_depth) / std_depth
|
| 65 |
+
# check if there are null values, then raise value error
|
| 66 |
+
if data.isnull().values.any():
|
| 67 |
+
raise ValueError("data contains null value")
|
| 68 |
+
|
| 69 |
+
data["event_type"] = data["event_type"]-1.0
|
| 70 |
+
data["event_type"] = data["event_type"].replace(2, 1)
|
| 71 |
+
data["event_type"] = data["event_type"].replace(3, 2)
|
| 72 |
+
# order_type = 0 -> limit order
|
| 73 |
+
# order_type = 1 -> cancel order
|
| 74 |
+
# order_type = 2 -> market order
|
| 75 |
+
return data, mean_size, mean_prices, std_size, std_prices, mean_time, std_time, mean_depth, std_depth
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def reset_indexes(dataframes):
|
| 79 |
+
# reset the indexes of the messages and orderbooks
|
| 80 |
+
dataframes[0] = dataframes[0].reset_index(drop=True)
|
| 81 |
+
dataframes[1] = dataframes[1].reset_index(drop=True)
|
| 82 |
+
return dataframes
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def sampling_quantity(dataframes, quantity=1000):
|
| 86 |
+
messages_df, orderbook_df = dataframes[0], dataframes[1]
|
| 87 |
+
|
| 88 |
+
# Calculate cumulative sum and create boolean mask
|
| 89 |
+
cumsum = messages_df['size'].cumsum()
|
| 90 |
+
sample_mask = (cumsum % quantity < messages_df['size'])
|
| 91 |
+
|
| 92 |
+
# Get indices where we need to sample
|
| 93 |
+
sampled_indices = messages_df.index[sample_mask].tolist()
|
| 94 |
+
|
| 95 |
+
# Update both dataframes efficiently using loc
|
| 96 |
+
messages_df = messages_df.loc[sampled_indices].reset_index(drop=True)
|
| 97 |
+
orderbook_df = orderbook_df.loc[sampled_indices].reset_index(drop=True)
|
| 98 |
+
|
| 99 |
+
return [messages_df, orderbook_df]
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def sampling_time(dataframes, time):
|
| 103 |
+
# Convert the time column to datetime format if it's not already
|
| 104 |
+
dataframes[0]['time'] = pd.to_datetime(dataframes[0]['time'], unit='s')
|
| 105 |
+
|
| 106 |
+
# Resample the messages dataframe to get data at every second
|
| 107 |
+
resampled_messages = dataframes[0].set_index('time').resample(time).first().dropna().reset_index()
|
| 108 |
+
|
| 109 |
+
# Resample the orderbook dataframe to get data at every second
|
| 110 |
+
resampled_orderbook = dataframes[1].set_index(dataframes[0]['time']).resample(time).first().dropna().reset_index(drop=True)
|
| 111 |
+
|
| 112 |
+
# Update the dataframes with the resampled data
|
| 113 |
+
dataframes[0] = resampled_messages
|
| 114 |
+
|
| 115 |
+
# Transform the time column to seconds
|
| 116 |
+
dataframes[0]['time'] = dataframes[0]['time'].dt.second + dataframes[0]['time'].dt.minute * 60 + dataframes[0]['time'].dt.hour * 3600 + dataframes[0]['time'].dt.microsecond / 1e6
|
| 117 |
+
dataframes[1] = resampled_orderbook
|
| 118 |
+
|
| 119 |
+
return dataframes
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def preprocess_data(dataframes, n_lob_levels, sampling_type, time=None, quantity=None):
|
| 123 |
+
dataframes = reset_indexes(dataframes)
|
| 124 |
+
# take only the first n_lob_levels levels of the orderbook and drop the others
|
| 125 |
+
dataframes[1] = dataframes[1].iloc[:, :n_lob_levels * cst.LEN_LEVEL]
|
| 126 |
+
|
| 127 |
+
# take the indexes of the dataframes that are of type
|
| 128 |
+
# 2 (partial deletion), 5 (execution of a hidden limit order),
|
| 129 |
+
# 6 (cross trade), 7 (trading halt) and drop it
|
| 130 |
+
indexes_to_drop = dataframes[0][dataframes[0]["event_type"].isin([2, 5, 6, 7])].index
|
| 131 |
+
dataframes[0] = dataframes[0].drop(indexes_to_drop)
|
| 132 |
+
dataframes[1] = dataframes[1].drop(indexes_to_drop)
|
| 133 |
+
|
| 134 |
+
dataframes = reset_indexes(dataframes)
|
| 135 |
+
|
| 136 |
+
# sample the dataframes according to the sampling type
|
| 137 |
+
if sampling_type == "time":
|
| 138 |
+
dataframes = sampling_time(dataframes, time)
|
| 139 |
+
elif sampling_type == "quantity":
|
| 140 |
+
dataframes = sampling_quantity(dataframes, quantity)
|
| 141 |
+
|
| 142 |
+
dataframes = reset_indexes(dataframes)
|
| 143 |
+
|
| 144 |
+
# drop index column in messages
|
| 145 |
+
dataframes[0] = dataframes[0].drop(columns=["order_id"])
|
| 146 |
+
|
| 147 |
+
# do the difference of time row per row in messages and subsitute the values with the differences
|
| 148 |
+
# Store the initial value of the "time" column
|
| 149 |
+
first_time = dataframes[0]["time"].values[0]
|
| 150 |
+
# Calculate the difference using diff
|
| 151 |
+
dataframes[0]["time"] = dataframes[0]["time"].diff()
|
| 152 |
+
# Set the first value directly
|
| 153 |
+
dataframes[0].iat[0, dataframes[0].columns.get_loc("time")] = first_time - 34200
|
| 154 |
+
|
| 155 |
+
# add depth column to messages
|
| 156 |
+
dataframes[0]["depth"] = 0
|
| 157 |
+
|
| 158 |
+
# we compute the depth of the orders with respect to the orderbook
|
| 159 |
+
# Extract necessary columns
|
| 160 |
+
prices = dataframes[0]["price"].values
|
| 161 |
+
directions = dataframes[0]["direction"].values
|
| 162 |
+
event_types = dataframes[0]["event_type"].values
|
| 163 |
+
bid_sides = dataframes[1].iloc[:, 2::4].values
|
| 164 |
+
ask_sides = dataframes[1].iloc[:, 0::4].values
|
| 165 |
+
|
| 166 |
+
# Initialize depth array
|
| 167 |
+
depths = np.zeros(dataframes[0].shape[0], dtype=int)
|
| 168 |
+
|
| 169 |
+
# Compute the depth of the orders with respect to the orderbook
|
| 170 |
+
for j in range(1, len(prices)):
|
| 171 |
+
order_price = prices[j]
|
| 172 |
+
direction = directions[j]
|
| 173 |
+
event_type = event_types[j]
|
| 174 |
+
|
| 175 |
+
index = j if event_type == 1 else j - 1
|
| 176 |
+
|
| 177 |
+
if direction == 1:
|
| 178 |
+
bid_price = bid_sides[index, 0]
|
| 179 |
+
depth = (bid_price - order_price) // 100
|
| 180 |
+
else:
|
| 181 |
+
ask_price = ask_sides[index, 0]
|
| 182 |
+
depth = (order_price - ask_price) // 100
|
| 183 |
+
|
| 184 |
+
depths[j] = max(depth, 0)
|
| 185 |
+
|
| 186 |
+
# Assign the computed depths back to the DataFrame
|
| 187 |
+
dataframes[0]["depth"] = depths
|
| 188 |
+
|
| 189 |
+
# we eliminate the first row of every dataframe because we can't deduce the depth
|
| 190 |
+
dataframes[0] = dataframes[0].iloc[1:, :]
|
| 191 |
+
dataframes[1] = dataframes[1].iloc[1:, :]
|
| 192 |
+
dataframes = reset_indexes(dataframes)
|
| 193 |
+
|
| 194 |
+
dataframes[0]["direction"] = dataframes[0]["direction"] * dataframes[0]["event_type"].apply(
|
| 195 |
+
lambda x: -1 if x == 4 else 1)
|
| 196 |
+
|
| 197 |
+
return dataframes[1], dataframes[0]
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def unnormalize(x, mean, std):
|
| 201 |
+
return x * std + mean
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
def one_hot_encoding_type(data):
|
| 205 |
+
encoded_data = torch.zeros(data.shape[0], data.shape[1] + 2, dtype=torch.float32)
|
| 206 |
+
encoded_data[:, 0] = data[:, 0]
|
| 207 |
+
# encoding order type
|
| 208 |
+
one_hot_order_type = torch.nn.functional.one_hot((data[:, 1]).to(torch.int64), num_classes=3).to(
|
| 209 |
+
torch.float32)
|
| 210 |
+
encoded_data[:, 1:4] = one_hot_order_type
|
| 211 |
+
encoded_data[:, 4:] = data[:, 2:]
|
| 212 |
+
return encoded_data
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def tanh_encoding_type(data):
|
| 216 |
+
data[:, 1] = torch.where(data[:, 1] == 1.0, 2.0, torch.where(data[:, 1] == 2.0, 1.0, data[:, 1]))
|
| 217 |
+
data[:, 1] = data[:, 1] - 1
|
| 218 |
+
return data
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def to_sparse_representation(lob, n_levels):
|
| 222 |
+
if not isinstance(lob, np.ndarray):
|
| 223 |
+
lob = np.array(lob)
|
| 224 |
+
sparse_lob = np.zeros(n_levels * 2)
|
| 225 |
+
for j in range(lob.shape[0] // 2):
|
| 226 |
+
if j % 2 == 0:
|
| 227 |
+
ask_price = lob[0]
|
| 228 |
+
current_ask_price = lob[j*2]
|
| 229 |
+
depth = (current_ask_price - ask_price) // 100
|
| 230 |
+
if depth < n_levels and int(lob[j*2]) != 0:
|
| 231 |
+
sparse_lob[2*int(depth)] = lob[j*2+1]
|
| 232 |
+
else:
|
| 233 |
+
bid_price = lob[2]
|
| 234 |
+
current_bid_price = lob[j*2]
|
| 235 |
+
depth = (bid_price - current_bid_price) // 100
|
| 236 |
+
if depth < n_levels and int(lob[j*2]) != 0:
|
| 237 |
+
sparse_lob[2*int(depth)+1] = lob[j*2+1]
|
| 238 |
+
return sparse_lob
|
utils/utils_model.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from models.mlplob import MLPLOB
|
| 2 |
+
from models.tlob import TLOB
|
| 3 |
+
from models.binctabl import BiN_CTABL
|
| 4 |
+
from models.deeplob import DeepLOB
|
| 5 |
+
from transformers import AutoModelForSeq2SeqLM
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def pick_model(model_type, hidden_dim, num_layers, seq_size, num_features, num_heads=8, is_sin_emb=False, dataset_type=None):
|
| 9 |
+
if model_type == "MLPLOB":
|
| 10 |
+
return MLPLOB(hidden_dim, num_layers, seq_size, num_features, dataset_type)
|
| 11 |
+
elif model_type == "TLOB":
|
| 12 |
+
return TLOB(hidden_dim, num_layers, seq_size, num_features, num_heads, is_sin_emb, dataset_type)
|
| 13 |
+
elif model_type == "BINCTABL":
|
| 14 |
+
return BiN_CTABL(60, num_features, seq_size, seq_size, 120, 5, 3, 1)
|
| 15 |
+
elif model_type == "DEEPLOB":
|
| 16 |
+
return DeepLOB()
|
| 17 |
+
else:
|
| 18 |
+
raise ValueError("Model not found")
|
visualizations/__pycache__/attentions.cpython-311.pyc
ADDED
|
Binary file (2.02 kB). View file
|
|
|
visualizations/attentions.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import matplotlib.pyplot as plt
|
| 2 |
+
import numpy as np
|
| 3 |
+
|
| 4 |
+
def plot_mean_att_distance(mean_att_dist):
|
| 5 |
+
'mean_att_dist shape: (num_layers, num_heads)'
|
| 6 |
+
num_layers = mean_att_dist.shape[0]
|
| 7 |
+
num_heads = mean_att_dist.shape[1]
|
| 8 |
+
# Create the plot
|
| 9 |
+
plt.figure(figsize=(10, 6))
|
| 10 |
+
|
| 11 |
+
for head in range(num_heads):
|
| 12 |
+
values = mean_att_dist[:, head]
|
| 13 |
+
plt.scatter(range(num_layers), values, label=f'Head {head}', s=20)
|
| 14 |
+
|
| 15 |
+
plt.xlabel('Network depth (layer)')
|
| 16 |
+
plt.ylabel('Mean attention distance (pixels)')
|
| 17 |
+
plt.xlim(0, num_layers - 1)
|
| 18 |
+
plt.ylim(0, 128)
|
| 19 |
+
|
| 20 |
+
# Customize legend
|
| 21 |
+
plt.legend(loc='lower right', ncol=2, fontsize='small')
|
| 22 |
+
|
| 23 |
+
# Add ellipsis to legend
|
| 24 |
+
handles, labels = plt.gca().get_legend_handles_labels()
|
| 25 |
+
handles.append(plt.Line2D([0], [0], marker='o', color='w', markerfacecolor='gray', markersize=5))
|
| 26 |
+
labels.append('...')
|
| 27 |
+
plt.legend(handles, labels, loc='lower right', ncol=2, fontsize='small')
|
| 28 |
+
plt.tight_layout()
|
| 29 |
+
|
| 30 |
+
return plt
|