
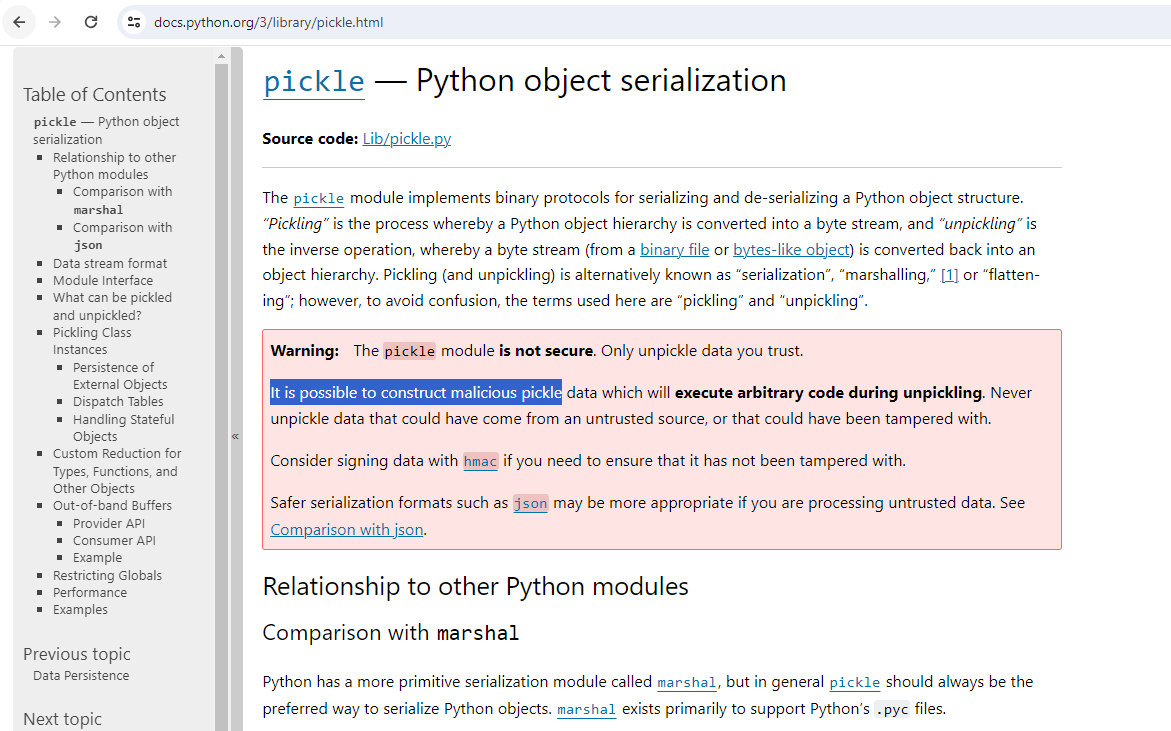
File size: 1,468 Bytes
5a41657 0358a53 bc0e3e2 f233b48 08acfc5 f233b48 a416380 09d27e7 a416380 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
---
tags:
- legal
---
## Model Details
- [](https://colab.research.google.com/drive/1dbfKhWmXaCcFsOrl7tlOKiLDkGuQhpZy?usp=sharing)
### Model Description
<!-- Provide a longer summary of what this model is. -->
Easy models to extract string text to keywords, it can be use for analysys user prompt then query fulltext search in indexed datasets, Apache Lucense, Sphinx...
- **Developed by:** **HuyRemy**
- **Funded by :** **HuyRemy**
- **Shared by :** **HuyRemy**
- **Model type:** **NLP**
### Direct Use
``` Python
import joblib
import nltk
nltk.download('punkt')
extract_keywords_model = joblib.load('huyremy_keywords_model.pkl')
# Sử dụng model để trích xuất từ khóa từ văn bản
text = """
Hello! I’m HuyRemy, a Software and Hardware Developer based
in Ha Noi. I have completed everything in Electronic Engineering and
and Electrical Engineering. In the fact I dev this mod for fun and...try it...it work. Good luck.
"""
keywords = extract_keywords_model(text)
# In ra màn hình những từ khóa có tần suất xuất hiện cao nhất
for keyword, count in keywords.most_common():
print(keyword)
```
### Attention: Google about me first (Google:HuyRemy) then...lookkkkkkkkkkkkk....what's it ? Uh Mine Jesssieeeeeee...
|