
Upload folder using huggingface_hub
Browse files- README.md +62 -37
- config.yaml +10 -0
- final_model.pth +3 -0
- model_iter_1000.pth +3 -0
- model_iter_1500.pth +3 -0
- model_iter_2000.pth +3 -0
- model_iter_2500.pth +3 -0
- model_iter_3000.pth +3 -0
- model_iter_3500.pth +3 -0
- model_iter_4000.pth +3 -0
- model_iter_4500.pth +3 -0
- model_iter_500.pth +3 -0
- model_iter_5000.pth +3 -0
- model_tensors.pt +3 -0
- spm_model.model +3 -0
- spm_model.vocab +0 -0
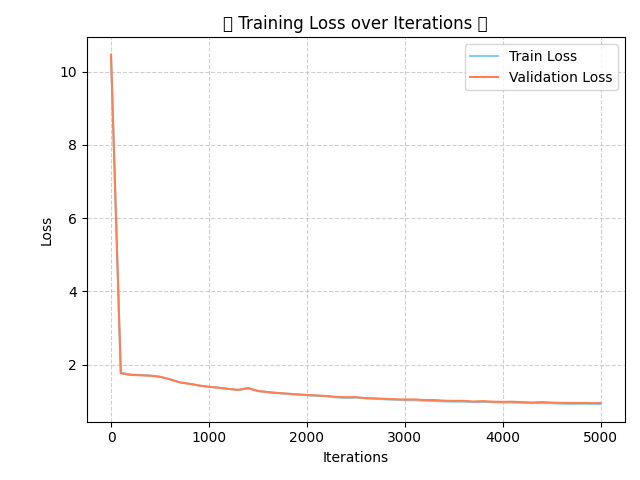
- training_plot.png +0 -0
README.md
CHANGED
|
@@ -1,49 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
|
| 2 |
-
#
|
| 3 |
|
| 4 |
-
This
|
| 5 |
|
| 6 |
-
|
| 7 |
-
- Trained using a byte-level vocabulary (size: 32000).
|
| 8 |
-
- Architecture: Transformer-based GPT model.
|
| 9 |
-
- Languages: Arabic (ar), Egyptian Arabic (ary).
|
| 10 |
-
- Training Data: Streamed Wikipedia dataset (limited to 10000 articles per language).
|
| 11 |
-
- Training Code: [Link to your training script/GitHub repo if available]
|
| 12 |
|
| 13 |
-
**
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
|
| 15 |
-
|
| 16 |
|
| 17 |
-
**
|
|
|
|
|
|
|
|
|
|
| 18 |
|
|
|
|
|
|
|
|
|
|
| 19 |
```python
|
| 20 |
-
import
|
| 21 |
-
from your_model_definition_script import GPTLanguageModel # Assuming you save model definition
|
| 22 |
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
model.
|
| 26 |
-
model.eval()
|
| 27 |
|
| 28 |
-
#
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 29 |
```
|
| 30 |
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
-
|
| 35 |
-
-
|
| 36 |
-
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
**
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
[
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language_model:
|
| 3 |
+
- causal
|
| 4 |
+
license: apache-2.0
|
| 5 |
+
tags:
|
| 6 |
+
- multilingual
|
| 7 |
+
- arabic
|
| 8 |
+
- darija
|
| 9 |
+
- transformers
|
| 10 |
+
- text-generation
|
| 11 |
+
model-index:
|
| 12 |
+
- name: Darija-LM
|
| 13 |
+
results: []
|
| 14 |
+
---
|
| 15 |
|
| 16 |
+
# Darija-LM
|
| 17 |
|
| 18 |
+
This is a multilingual language model trained on Arabic and Darija (Moroccan Arabic) Wikipedia datasets.
|
| 19 |
|
| 20 |
+
## Model Description
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 21 |
|
| 22 |
+
[**TODO: Add a detailed description of your model here.**]
|
| 23 |
+
For example, you can include:
|
| 24 |
+
- Model architecture: GPT-like Transformer
|
| 25 |
+
- Training data: Arabic and Darija Wikipedia (20231101 snapshot)
|
| 26 |
+
- Tokenizer: SentencePiece (BPE, vocab size: 32000)
|
| 27 |
+
- Training parameters: [Specify hyperparameters like learning rate, batch size, layers, heads, etc.]
|
| 28 |
|
| 29 |
+
## Intended Uses & Limitations
|
| 30 |
|
| 31 |
+
[**TODO: Describe the intended uses and limitations of this model.**]
|
| 32 |
+
For example:
|
| 33 |
+
- Intended use cases: Text generation, research in multilingual NLP, exploring low-resource language models.
|
| 34 |
+
- Potential limitations: May not be suitable for production environments without further evaluation and fine-tuning, potential biases from Wikipedia data.
|
| 35 |
|
| 36 |
+
## How to Use
|
| 37 |
+
|
| 38 |
+
[**TODO: Add instructions on how to load and use the model.**]
|
| 39 |
```python
|
| 40 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
|
|
|
| 41 |
|
| 42 |
+
model_name = "Duino/Darija-LM" # or path to your saved model locally
|
| 43 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 44 |
+
model = AutoModelForCausalLM.from_pretrained(model_name)
|
|
|
|
| 45 |
|
| 46 |
+
# Example generation code (adapt as needed based on your model and tokenizer)
|
| 47 |
+
# input_text = "مرحبا بالعالم" # Example Arabic/Darija input
|
| 48 |
+
# input_ids = tokenizer.encode(input_text, return_tensors="pt").to("cuda" if torch.cuda.is_available() else "cpu")
|
| 49 |
+
# output = model.generate(input_ids, max_length=50, num_beams=5, no_repeat_ngram_size=2, early_stopping=True)
|
| 50 |
+
# generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
|
| 51 |
+
# print(generated_text)
|
| 52 |
```
|
| 53 |
|
| 54 |
+
## Training Details
|
| 55 |
+
|
| 56 |
+
[**TODO: Provide details about the training process.**]
|
| 57 |
+
- Training data preprocessing: [Describe tokenization, data splitting, etc.]
|
| 58 |
+
- Training procedure: [Optimizer, learning rate schedule, number of iterations, etc.]
|
| 59 |
+
- Hardware: [Specify GPUs or TPUs used]
|
| 60 |
+
|
| 61 |
+
## Evaluation
|
| 62 |
+
|
| 63 |
+
[**TODO: Include evaluation metrics if you have them.**]
|
| 64 |
+
- [Metrics and results on a validation set or benchmark.]
|
| 65 |
+
|
| 66 |
+
## Citation
|
| 67 |
+
|
| 68 |
+
[**TODO: Add citation information if applicable.**]
|
| 69 |
+
|
| 70 |
+
## Model Card Contact
|
| 71 |
+
|
| 72 |
+
[**TODO: Add your contact information.**]
|
| 73 |
+
- [Your name/organization]
|
| 74 |
+
- [Your email/website/Hugging Face profile]
|
config.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_name_or_path: Duino/Darija-LM
|
| 2 |
+
architectures:
|
| 3 |
+
- GPTLanguageModel
|
| 4 |
+
block_size: 256
|
| 5 |
+
dropout: 0.2
|
| 6 |
+
n_embd: 384
|
| 7 |
+
n_head: 6
|
| 8 |
+
n_layer: 6
|
| 9 |
+
tokenizer_class: SentencePieceTokenizer
|
| 10 |
+
vocab_size: 32000
|
final_model.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2751195ca13cd0111deeda1e3a34c3de467dfb0f44d8eb93e41a24657606ffb3
|
| 3 |
+
size 150904870
|
model_iter_1000.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2354ef1b9bdd6bfc716f8f4cbf8f5fe718616f5f7e8605d41f84a48f9874a9e5
|
| 3 |
+
size 150905726
|
model_iter_1500.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a4a4bd0ad71a61324cf0e984d516d9ddd5ab5e8c659cdb933b92d9d63d83e312
|
| 3 |
+
size 150905726
|
model_iter_2000.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1f66f05df8482b915f9be6bd2ece04ad1f9799adc39be02da1835566707e8d9d
|
| 3 |
+
size 150905726
|
model_iter_2500.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1c01947b20d83a85f78333181f6c9456fd77d4207959167de66a03836ee84658
|
| 3 |
+
size 150905726
|
model_iter_3000.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cc541316b414e1ea00546d04806b6fda6333faaa80a73af77b9ca666d65033f8
|
| 3 |
+
size 150905726
|
model_iter_3500.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a41ce5eecc0c240ffcbf96efe547f3192ba3de3c516916aa46509c0bf626ae08
|
| 3 |
+
size 150905726
|
model_iter_4000.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dc9b5424fdf7517b59c10c76fff47ba2c90734ea5a36337a3b13dfd91c87691f
|
| 3 |
+
size 150905726
|
model_iter_4500.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:196538c2e040feac1470f3ab78dc2544c9bd548c335e9b5da72c757aa6f807ef
|
| 3 |
+
size 150905726
|
model_iter_500.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:af1c9ac435e999760164916c9a1235c88505fa863c40d343e4291e4e2b4d00a9
|
| 3 |
+
size 150905512
|
model_iter_5000.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c8c40311a49aa3cf3ba5be802f581a738f7d2f3696b7b16f2388ce3e15703a35
|
| 3 |
+
size 150905726
|
model_tensors.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:639206b9cdfc1b02f278ca1457a4e48ef050e506bb994be08a23701143ff80fd
|
| 3 |
+
size 150947986
|
spm_model.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b622ee3438740c316c30cace8fbf9a133233e7b4dff65b4bc29ddb26f50f5a6d
|
| 3 |
+
size 872745
|
spm_model.vocab
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_plot.png
ADDED
|